Harrie's Hoekje
Quarto
Over twee blogs die ik de laatste maand met Quarto gemaakt heb
Bayes en Stan
Over het werken met Bayesiaanse analyse in Stan.
Geografische analyse van risico's met INLA
Paula Moraga laat zien hoe je geografische gegevens kunt analyseren met het programma INLA
BayesRules
Een korte bespreking van Bayes Rules!
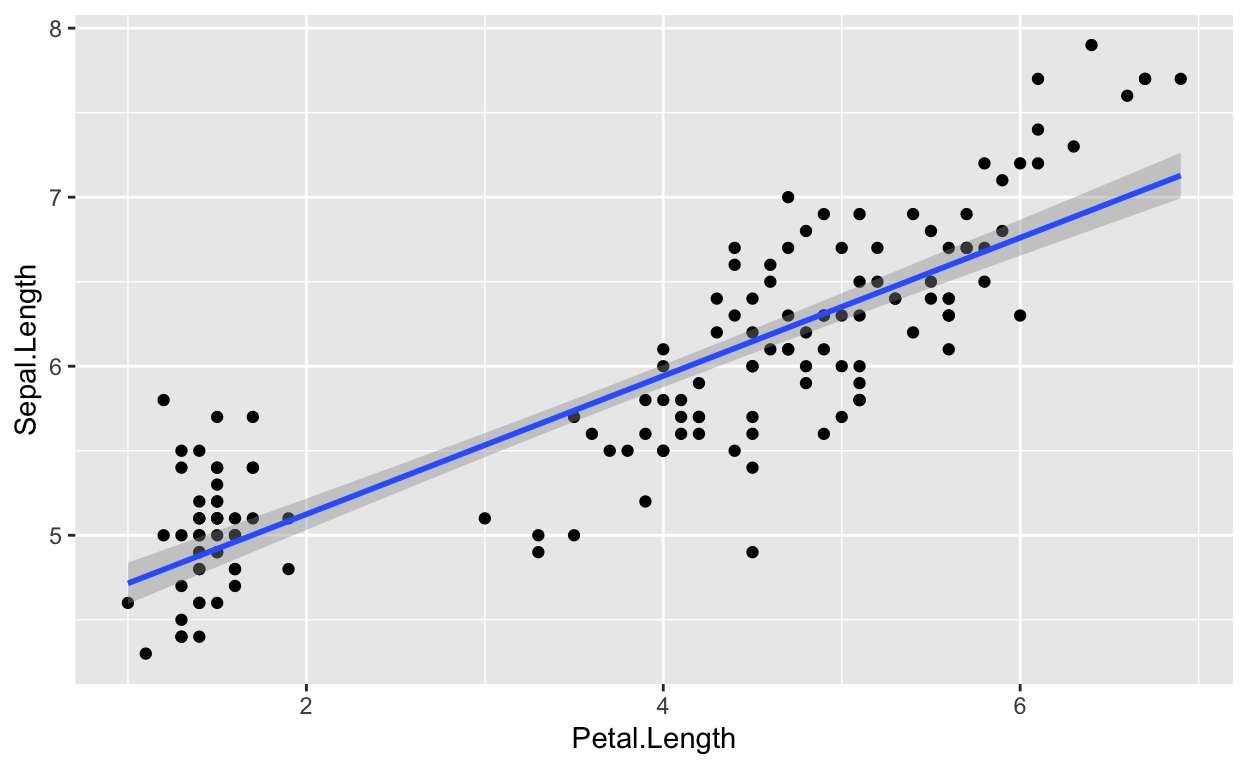
ggplot stap voor stap
Een GGPLOT2 handleiding om mooi te kunnen plotten in R.
Van distill naar quarto?
Een blog maken met quarto.
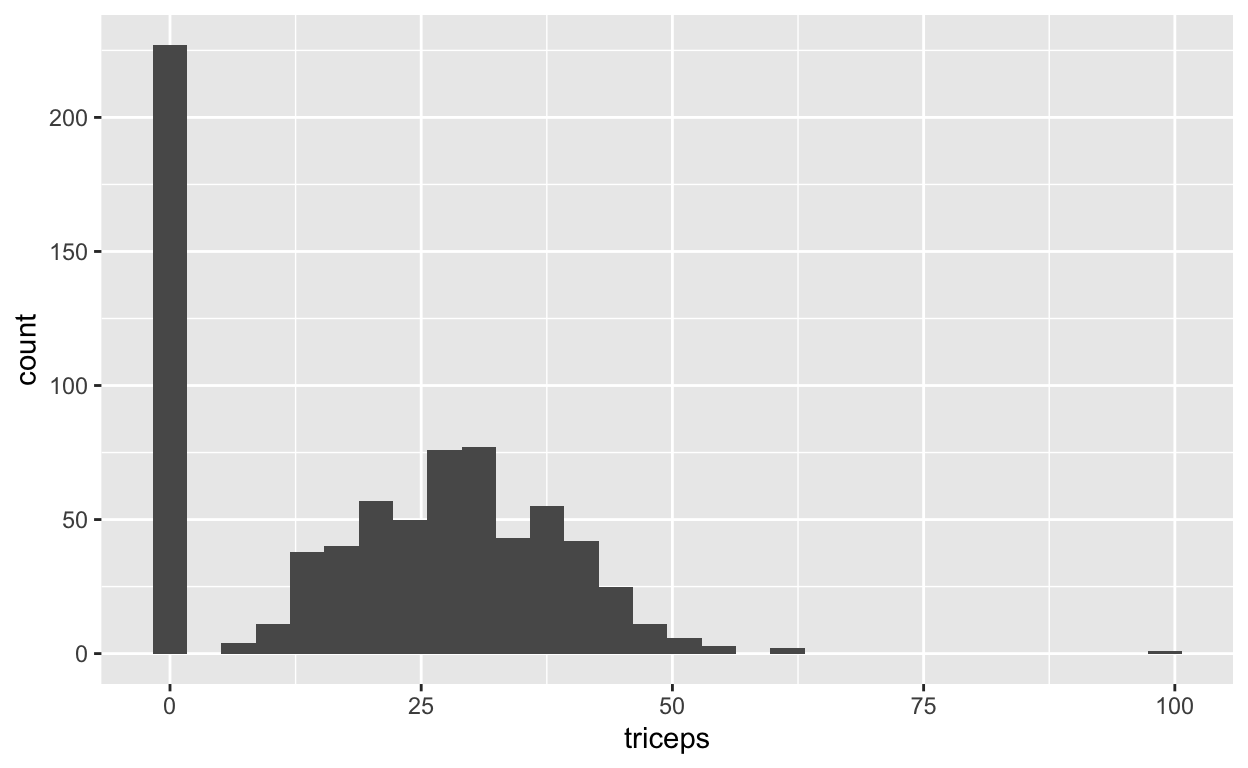
Missende waarden
Over het pakket `mice` en missende waarden
Kaarten maken met R
Hieronder een korte introductie op hoe je kaarten maakt met R, met name met het pakket `sf`.
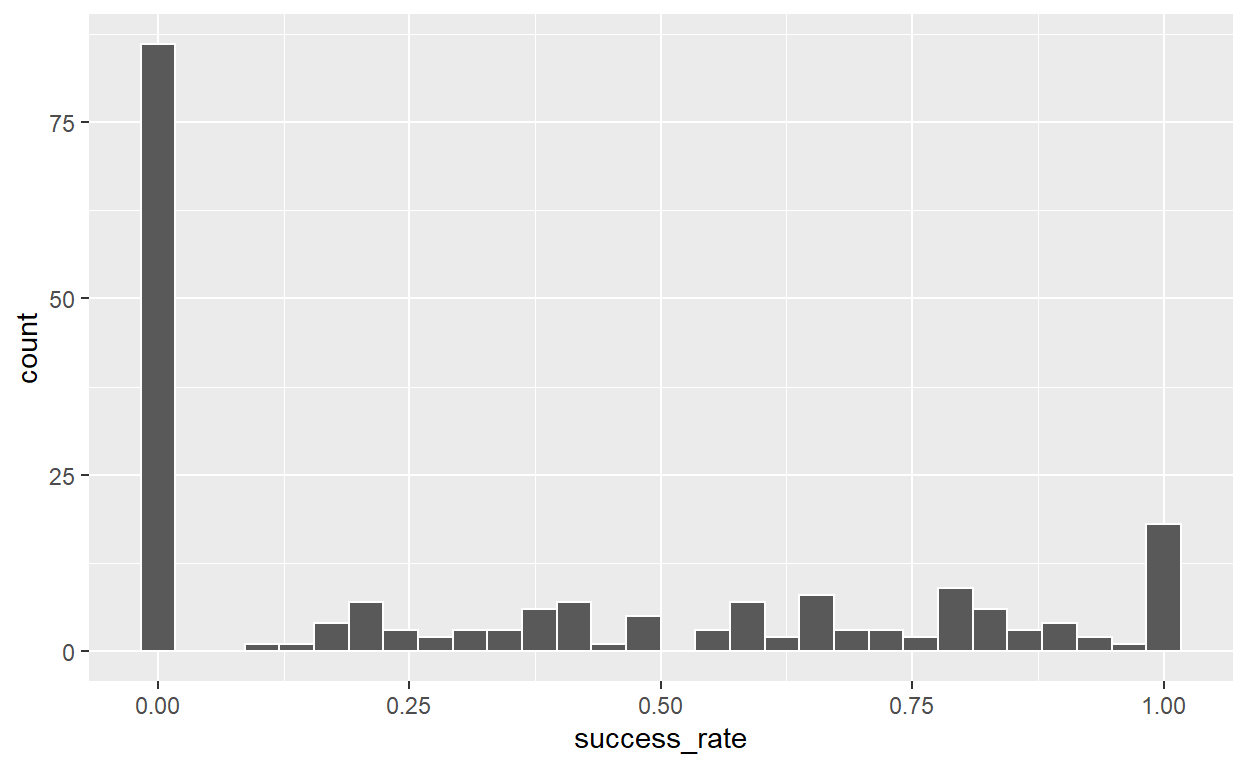
Hierarchische logistische regressie met Bayes
Dit is een blog over hoe hiërarchische logistische regressie werkt met gebruik van Bayesiaanse technieken.
Naïve Bayesiaanse classificatie
In deze blog wordt getoond hoe Naïeve Bayesiaanse classificatieanalyse werkt.
Wat kun je met Bayes?
In deze blog wordt getoond wat je met Bayes wetenschappelijk kunt: schatten, testen en voorspellen.
Bayes' principes
Een blog over de principes van de Bayesiaanse theorie
Machine Learning Workflow
Deze blog is een inleiding op de workflow van Machine Learning.

Regressie en nog zo iets
Dit is een blog naar aanleiding van Gelman/Hill/Vehtari nieuwe boek Regresion and other stories
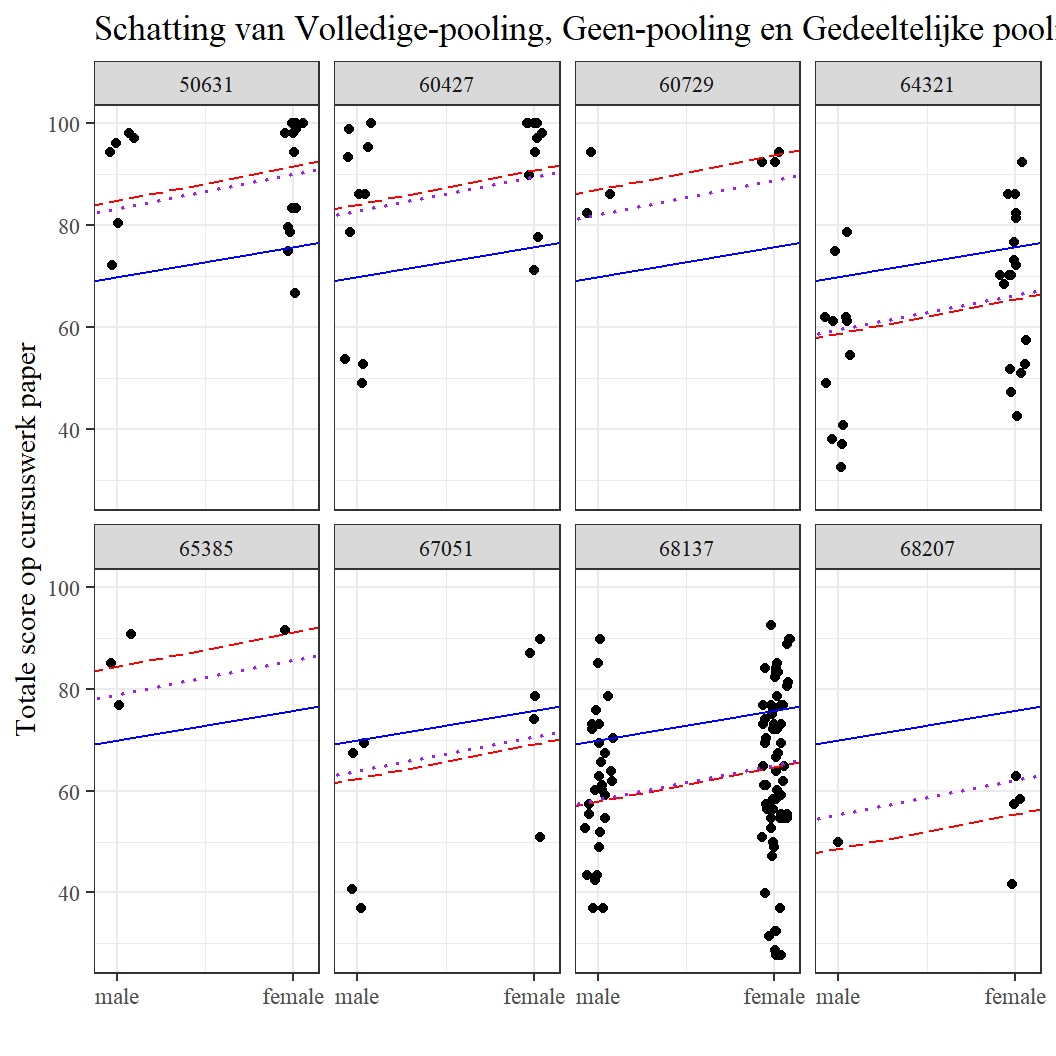
Introductie op multilevel modelleren met gebruik van **rstanarm**: Een tutorial voor onderwijsonderzoekers
Een tutorial over multilevel Bayes

Latente Groei Modeling
Dit is een blog over Latente Groei Modeling van longitudinale data van alcoholgebruik van jongeren
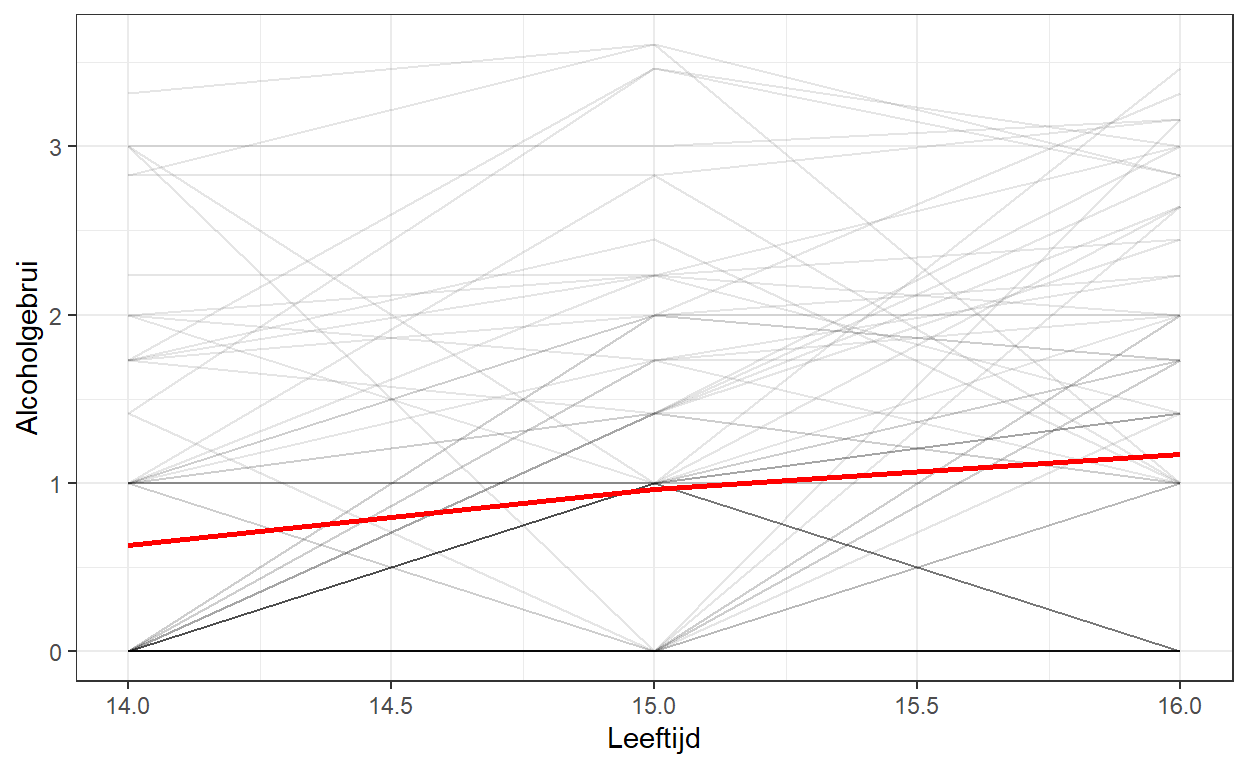
Multilevel modeling
Dit is een post over multilevel analyse van longitudinale data met betrekking tot alcoholgebruik van jongeren.
Opschonen en ontrafelen
Een post over opschonen en ontrafelen van data
Rmarkdown en Officedown
Een blog over documentatie en hoe ze dat in de farmaceutische industrie kunnen doen
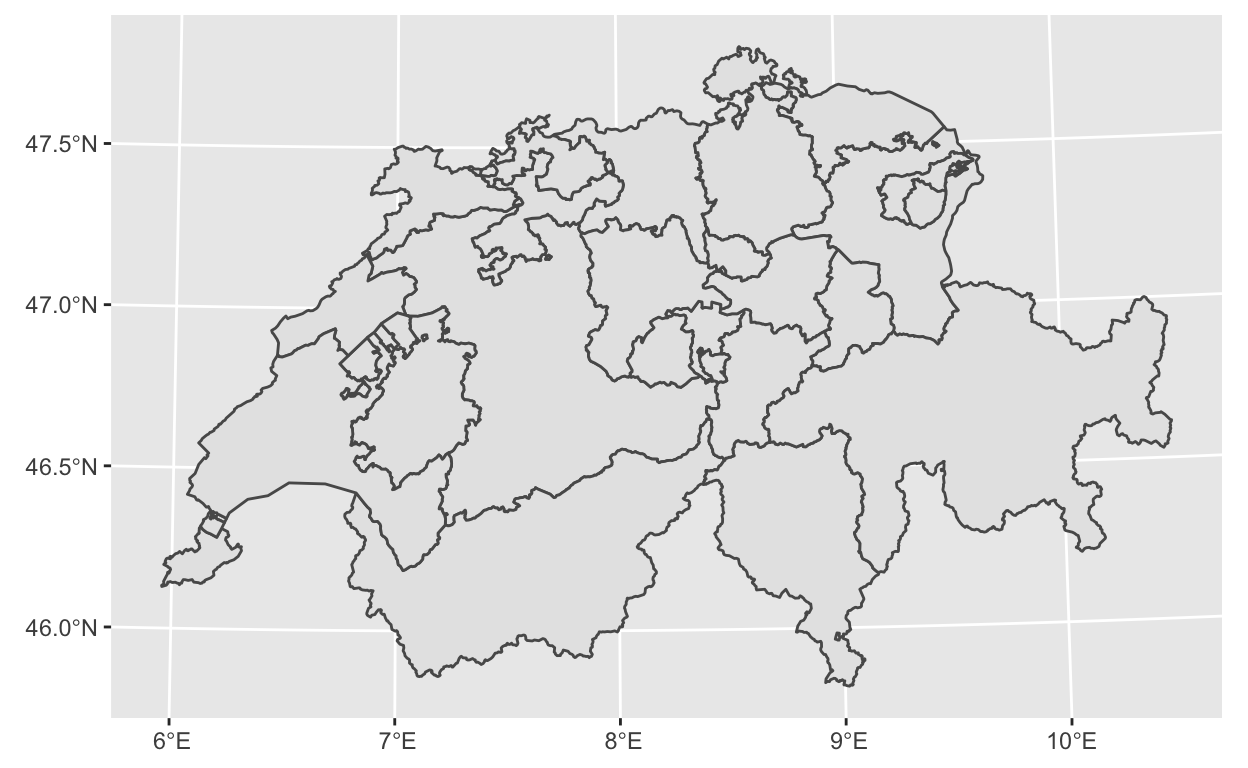
Kaart van Zwitserland
Dit is een mooie blog van Giulia Ruggeri over kaarten maken met `ggplot2` en `sf`, in dit geval van Zwitserland
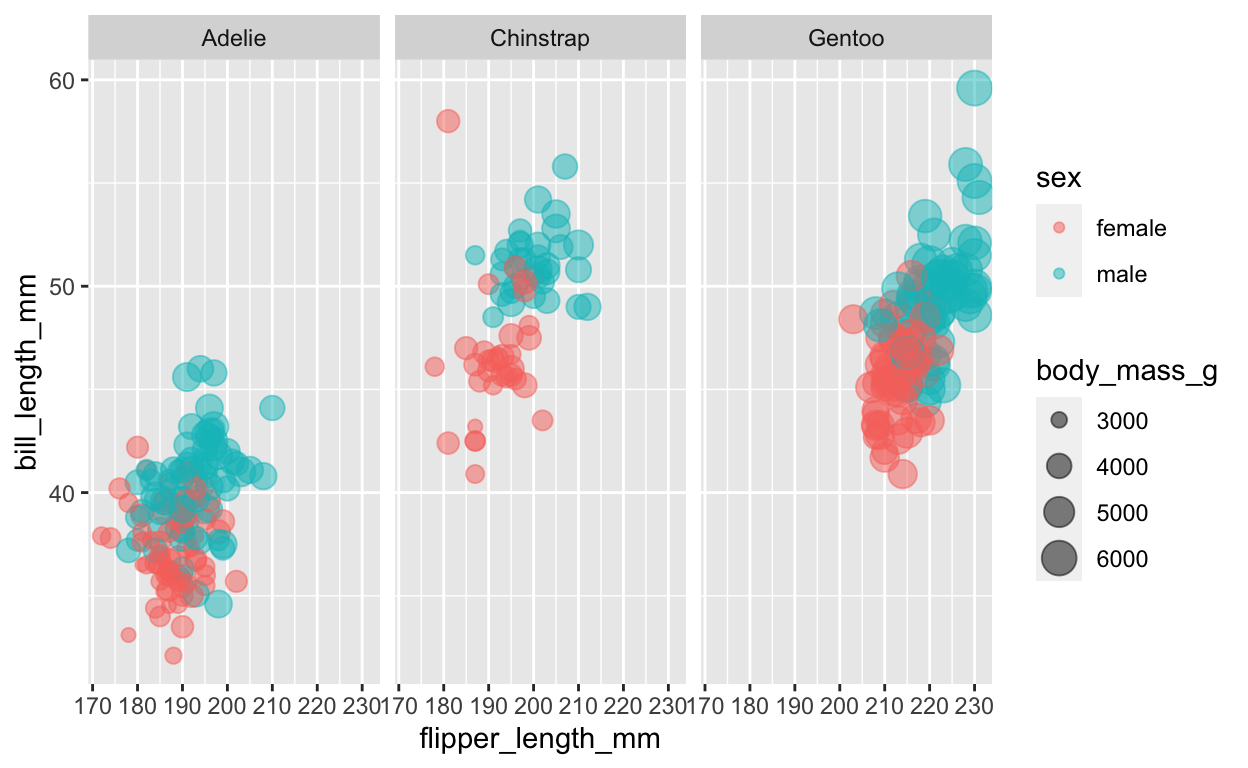
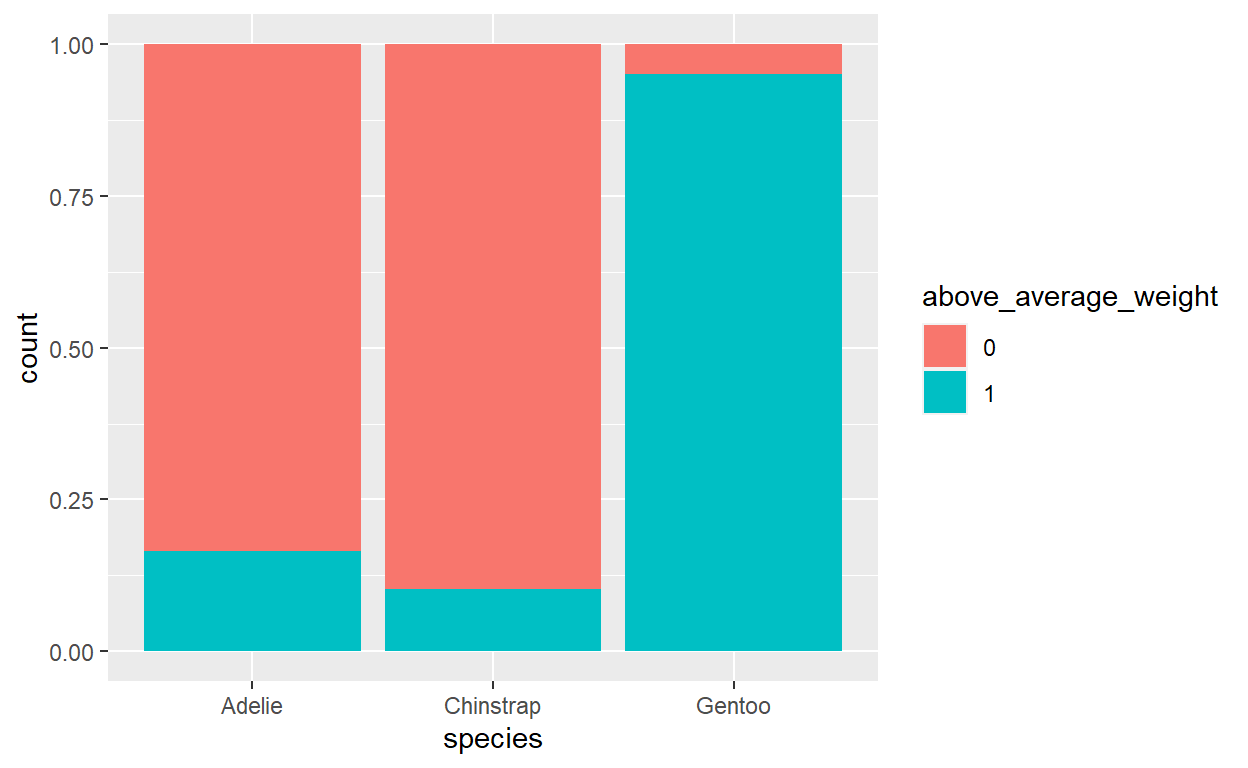
Classificeren van Palmer penguins
De laatste tijd heeft Julia Silge een aantal videoopnamen gemaakt die laten zien hoe het `tidymodels` raamwerk is te gebruiken.Het zijn opnamen over de eerste stappen in het modelleren tot hoe complexe modellen zijn te evalueren. Deze videoopname is goed voor mensen die net beginnen met `tidymodels`. Ze maakt daarbij gebruik van een #TidyTuesday dataset over pinguïns. Hier gaat het om classificeren.
Verzekeringskosten
Dit is de blog die [Arta Seyedan op 14 februari 2021 R-bloggers](https://www.r-bloggers.com/2021/02/using-tidymodels-to-predict-health-insurance-cost/) schreef en die ik wat bewerkt en vertaald heb.
Classificeren met Tidymodels
Dit is bewerking van een blog die [Rahul Raoniar, Towards data science](https://towardsdatascience.com/modelling-binary-logistic-regression-using-tidymodels-library-in-r-part-1-c1bdce0ac055) begin 2021 schreef.
Tidymodels opnieuw
Blog van Rebecca Barter onder de titel 'Tidymodels: tidy machine learning in R'
Machine Learning met Tidymodels
Enkele blogs zal ik aan Machine Learning besteden. Ik zal enkele tutorials bewerken die mij veel geleerd hebben. Lisa Lendway, van wie ik al twee keer eerder materiaal gebruikte, schreef een goede blog over tidymodels. Zie hieronder.
GitHub voor samenwerking
Lisa Lendway heeft een aantal interessante repositories op haar GitHub account staan, [zie hier](https://github.com/llendway). Ze zijn vaak kort, maar helder en concreet. Haar stijl en de consistentie daarin bevallen mij zeer. Van haar manier van doen leer ik veel. Zij maakt haar stukken vaak voor haar statistieklessen en deelt zo haar kennis met haar studenten en anderen buiten haar klas. Ik heb mij voorgenomen om er een aantal goed te lezen, te vertalen en te bewerken waar nodig, en deze op mijn website over te nemen. Vorige maand deed ik dat al met een blof over Distill en nu een over GitHub.
Website met distill
Website met blog maken
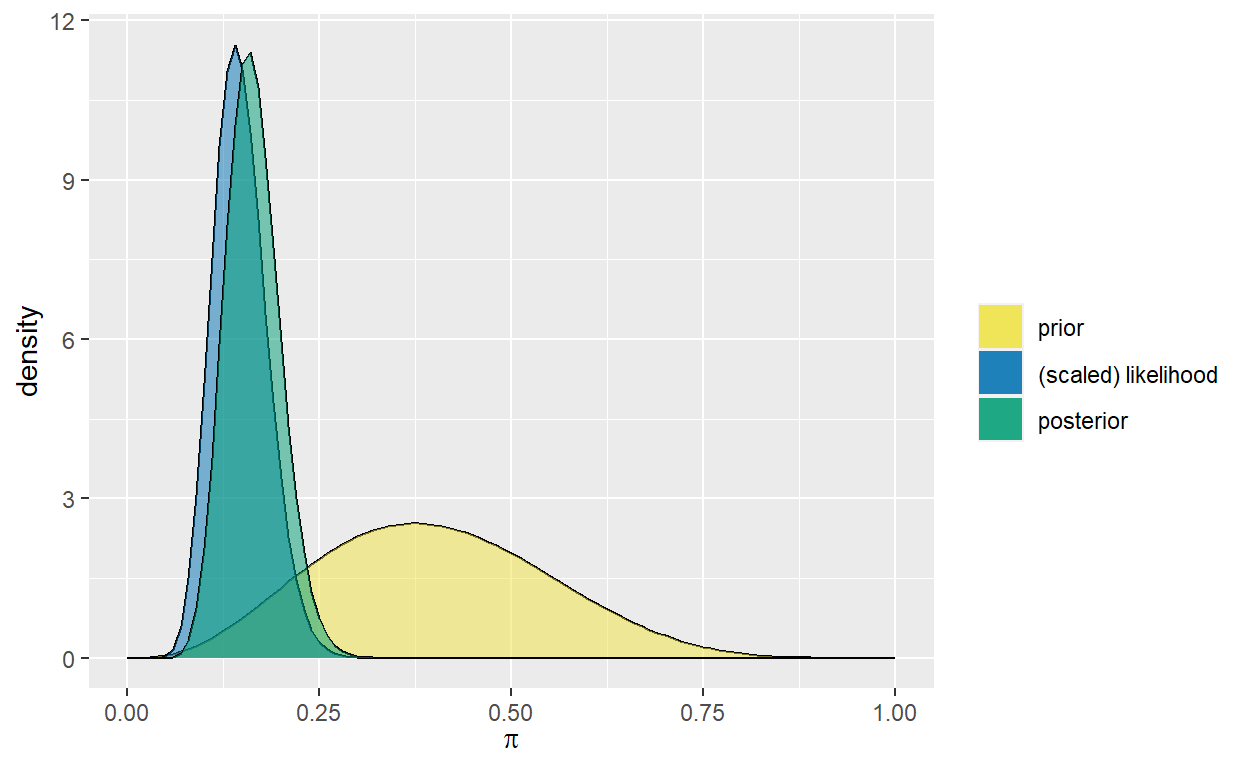
Testen met Bayes
Resultaten testen met Bayesiaanse onderzoekstechnieken.
Het Goede, het Slechte en het Lelijke: Data effectief visualiseren en communiceren
Shirin Elsinghorst schreef deze blog onlangs op [Codecentric](https://blog.codecentric.de/2020/10/goodbadugly/). Omdat ze op mijn werk de vormgeving van de uitgaven hebben aangepast, wilde ik het maken van figuren aan de nieuwe kleursetting van mijn werk aanpassen. Shirin's blog was een mooie oefenplaats voor mij. Tegelijk is het een mooie introductie op datavisualisatie en daarom de moeite waard het in het Nederlands te bewerken. [Hier](https://docs.google.com/presentation/d/e/2PACX-1vR4pD2EmW9Gzxr1Q3qwgjEYkU64o2-ThlX1mXqfNQ2EKteVUVt6Qg2ImEKKi9XLv-Iutb3lD8esLyU7/pub?start=false&loop=false&delayms=3000&slide=id.g58b36409ef_0_0) vind je de presentatie die zij zelf hierover op 20 oktober 2020 in Duitsland gaf.

Een eenvoudige introductie op `tidymodels`
Edgar Ruiz' eenvoudige introductie op machine learning met de inzet van het pakket `tidymodels`.
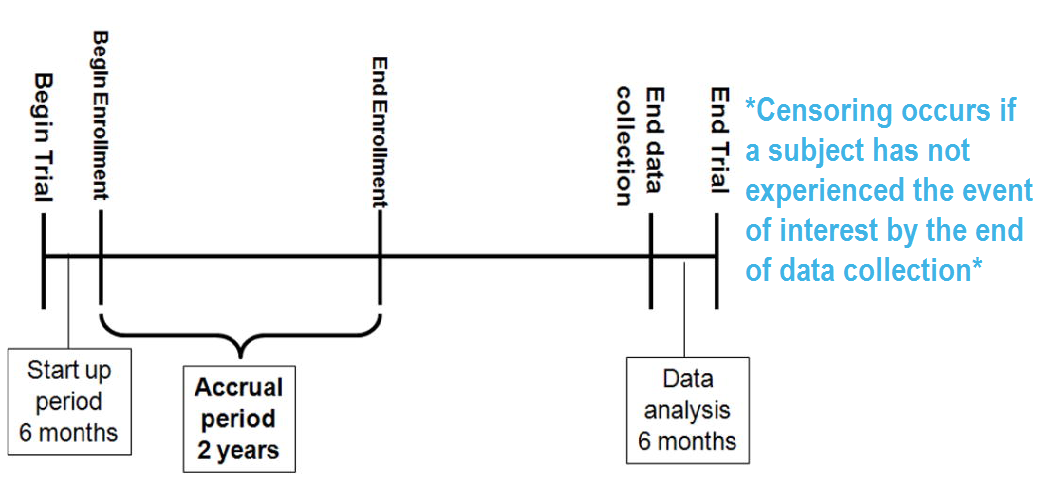
Survival analyse met R
Dit is een deel van een tutorial die Emily Zabore schreef over survival analyse met R.
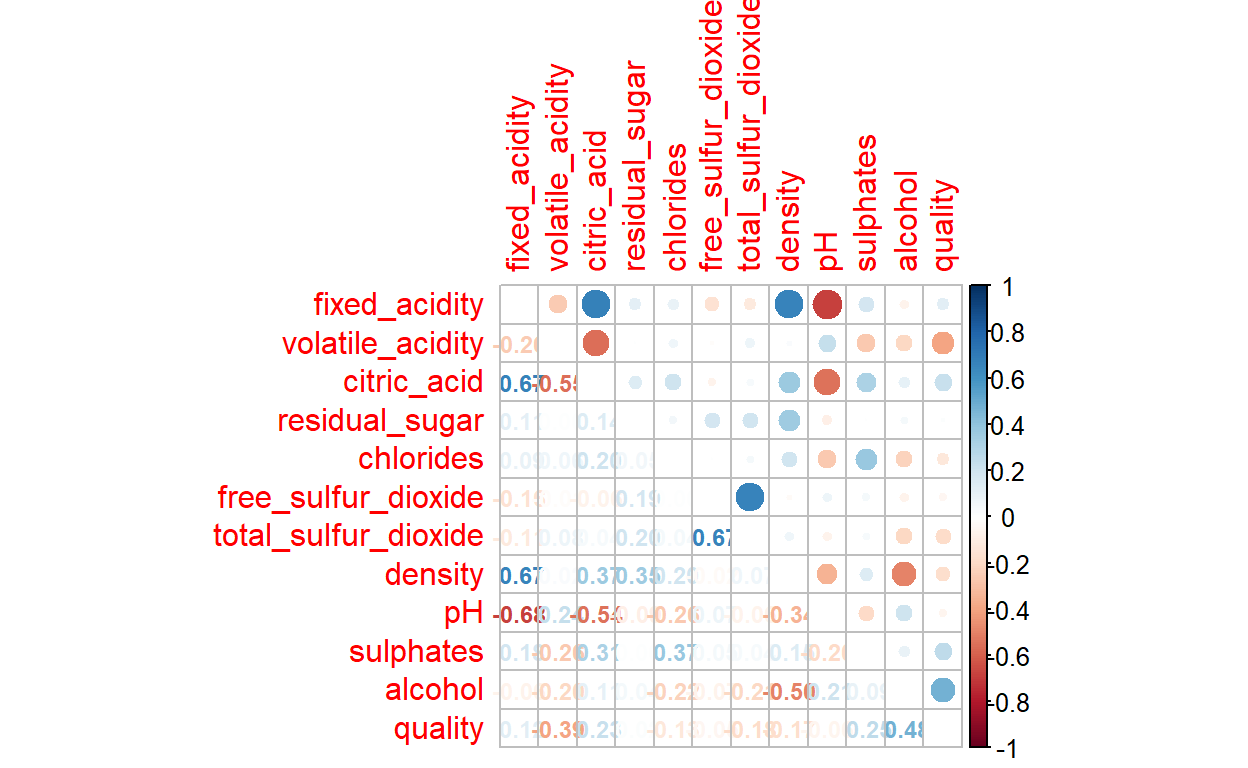
Grafieken
Hier een serie grafieken die je kunt maken. Dit is gebaseerd op blog van het Urban Institute in de Verenigde Staten. Zij maken hun grafieken altijd op eenzelfde manier. Hoe ze dat doen kan je hierlezen
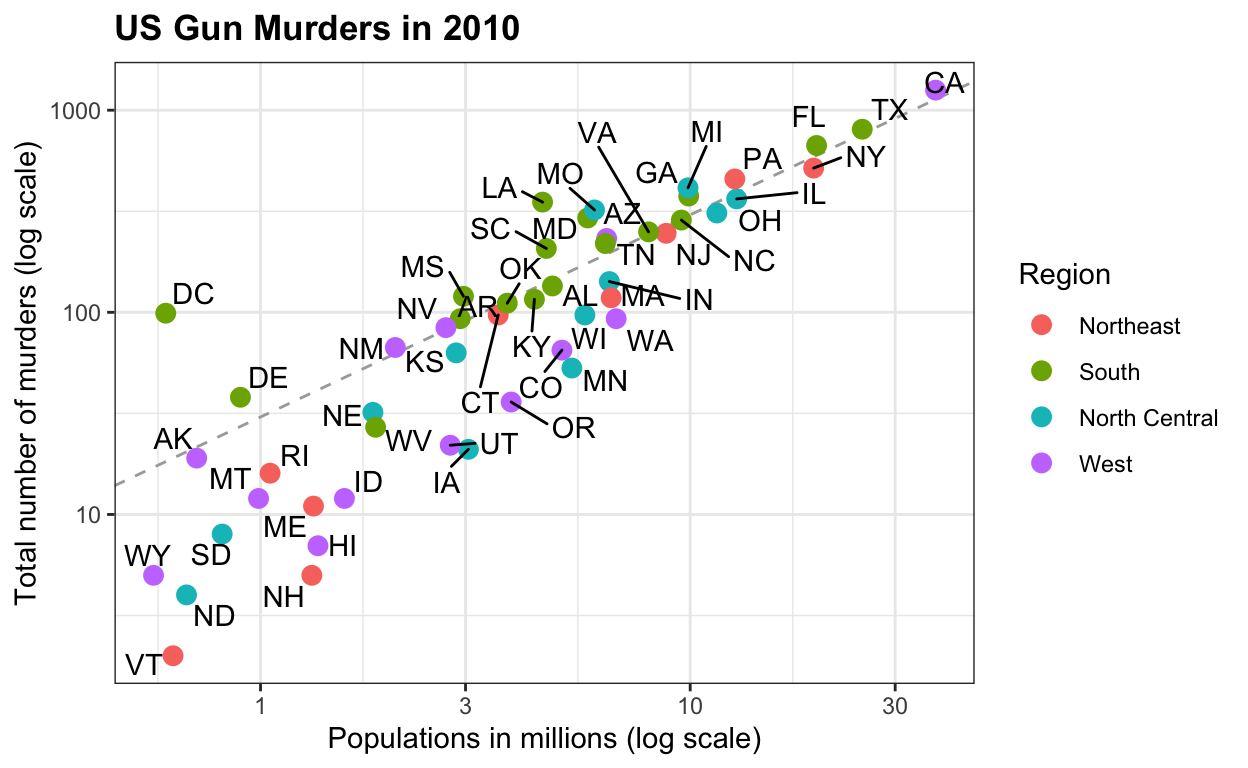
dslabs
Een aantal mooie grafieken uit het goede data-analyseboek van Rafa Irizarri (Harvard University)
Beste Boeken 2019
A short description of the post.
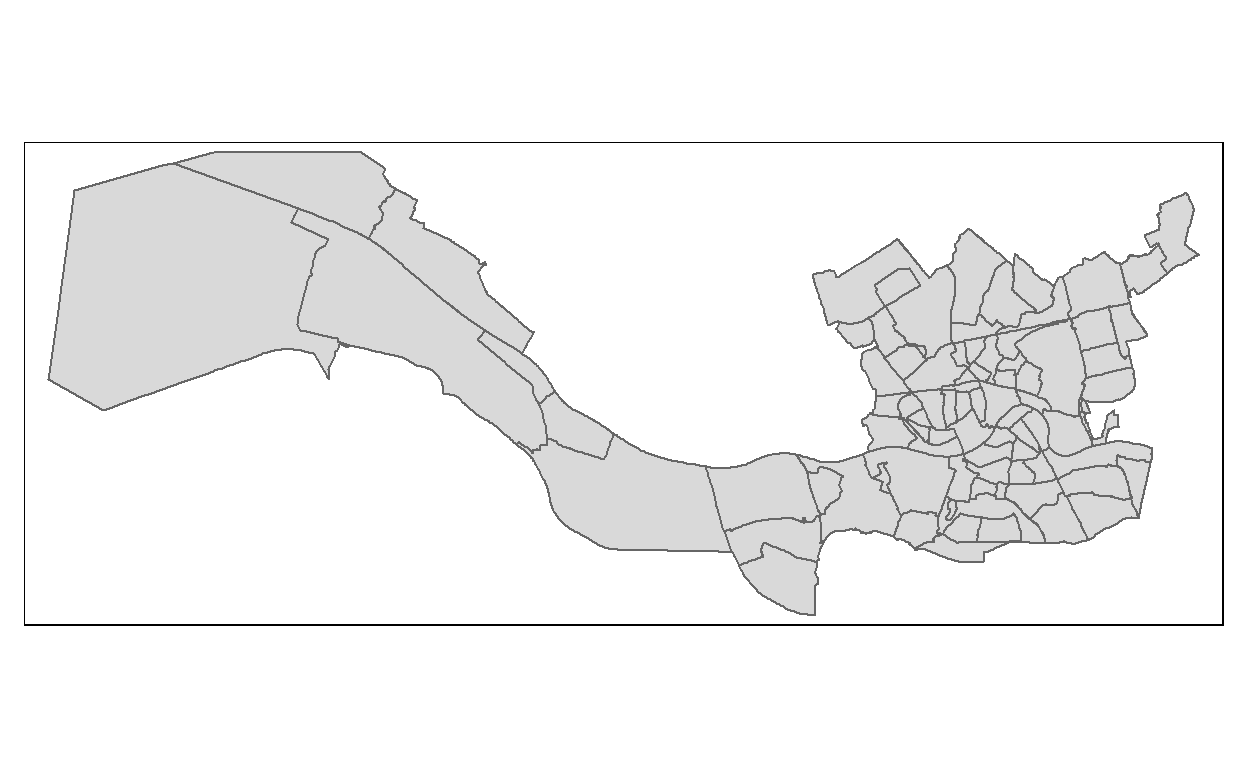
R als een Gis
Over ruimtelijke data en het gebruik van R als een GIS

Bayes'basis
Over statistiek en waarschijnlijkheid op de eenvoudige manier.

Sf, ggplot en tmap
Over het maken van kaarten van Nederland met nieuwe pakketten en mogelijkheden.
Geocomputation
Bespreking van het fantastische boek Geocomputation with R
Xaringan
Een mooie presentatie geven met het pakket Xaringan
Bookdown
Hoe maak je een boek. Bookdown is het pakket van R waar dat mee kan. Hier enkele tips om dat te doen
Websites maken in R
Met R kun je ook website maken. Maar hoe doe je dat? Emily Zabor schreef hierover een leerzaam blog dat ik hier licht heb bewerkt en aangevuld.
Interactieve grafiek met plotly
In deze twee maanden wilde ik toch eens kijken naar interactieve mogelijkheden die het programma R/RStudio ons biedt. `Plotly` is zo'n mogelijkheid en daarover gaat dit blog. `Shiny` is de andere mogelijkheid en daar zal ik een volgende keer aandacht aan besteden. `Plotly` heeft een eigen website waar veel informatie over het programma is te vinden [hier adres website](https://plot.ly/). Er is ook een uitgebreide handleiding over `Plotly` geschreven [hier handleiding](https://plotly-r.com/the-plotly-cookbook.html). Onlangs stond er op de blog van RBloggers een goede introductie van Laura Ellis, die mij veel vertelde over het gebruik van `Plotly`. Haar bijdrage [zie hier](https://www.r-bloggers.com/create-interactive-ggplot2-graphs-with-plotly/) heb ik hier naar het Nederlands overgezet en hier en daar iets bewerkt.
BBC en data-journalisme
Een blog over hoe de BBC omgaat met visualisatie en data-journalisme
Data visualisatie. Een practische introductie
Naar aanleiding van het nieuwe boek van Kieran Healey. Data visualization/A Practical Introduction.
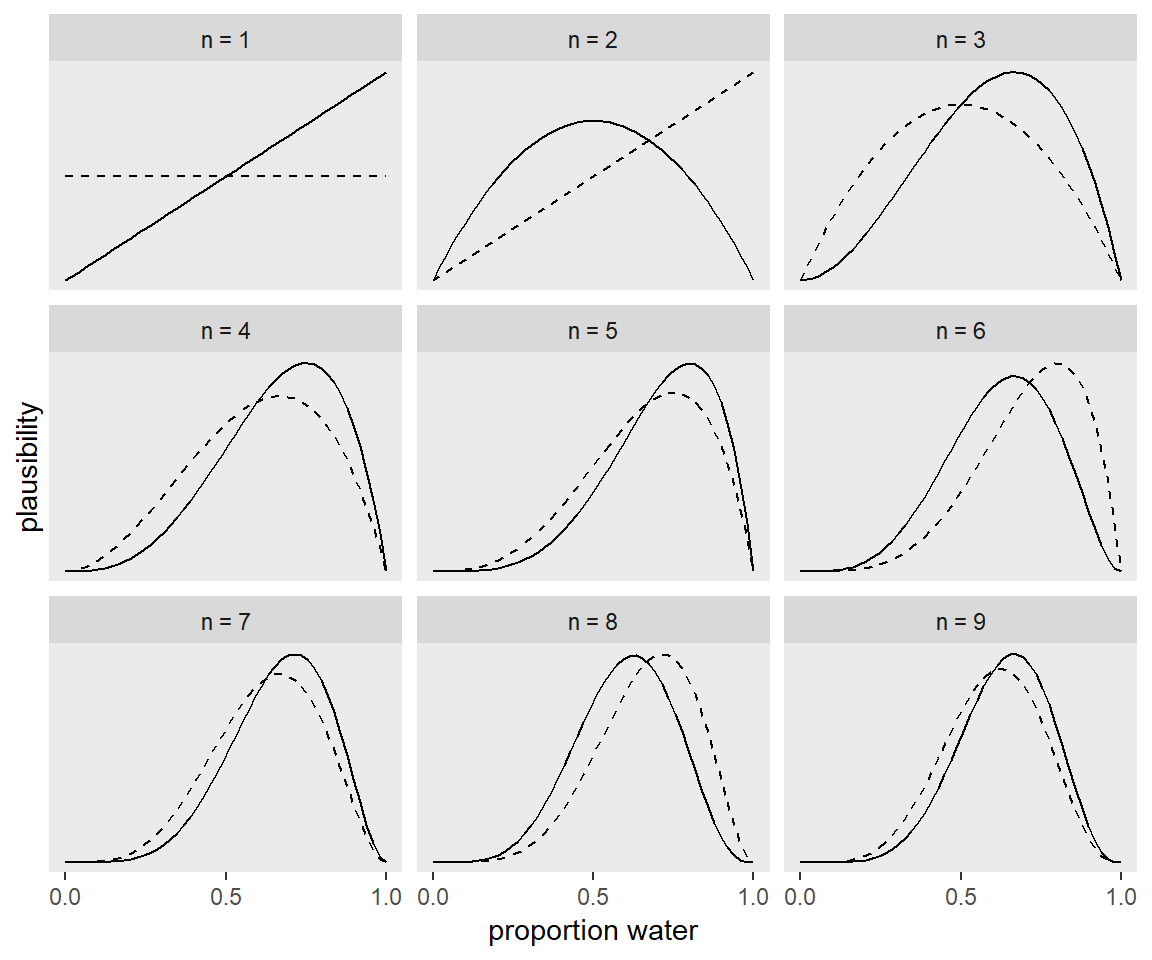
Statistisch omdenken
Over 'Statistical rethinking' van Richard McElreath (2016).
Communiceren met RMarkdown
RMarkdown is de nieuwe manier om diverse wetenschappelijke producten te delen met anderen. Het kan op verschillende manieren gereproduceerd worden en het kan de opbrengsten aantrekkelijk communiceren naar de buitenwereld. Hier een introductie op de werkwijze en enkele mogelijke producten.
Bewerking geografische data in R: Nieuwe ontwikkelingen
Het nieuwe R sf-pakket, dat sp vervangt om met geografische objecten om te gaan, is ontworpen om makkelijk met Tidyverse om te gaan. Hier laat ik zien hoe sf-objecten als data-frames worden opgeslagen en jou in staat stelt om met ggplot2, dplyr en tidyr te werken. Ook het R-pakket tmap biedt veel nieuwe mogelijkheden.

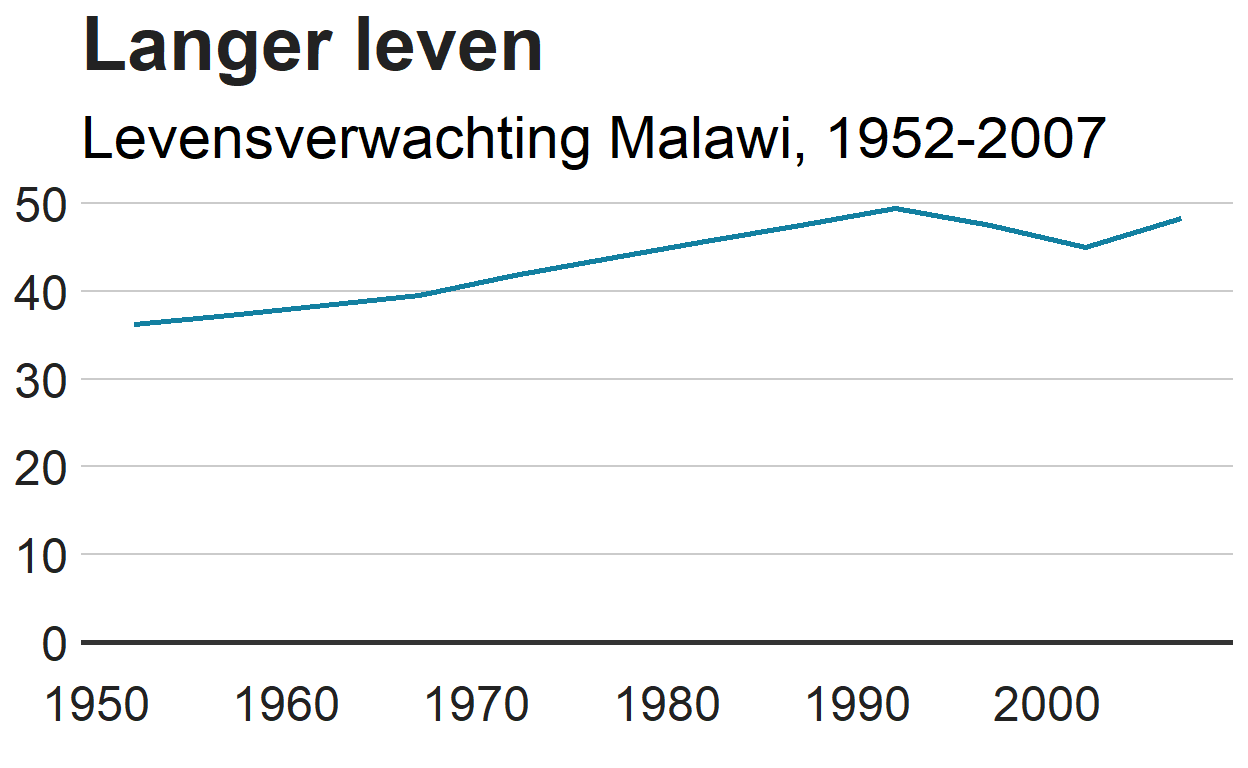
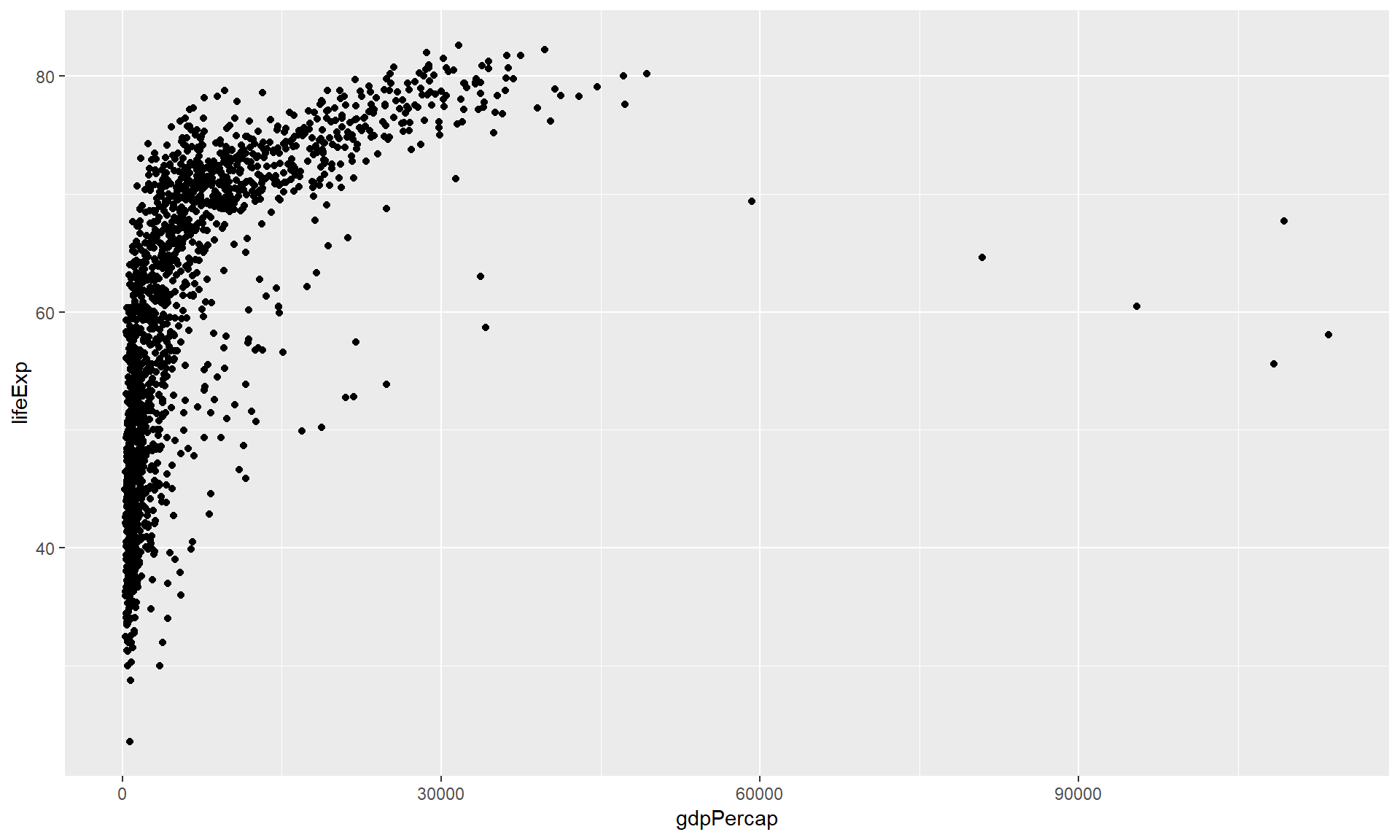
Visualisatie met inzet van Gapminder
Een voorbeeld van datavisualisatie: Trends op het gebied van de wereldgezondheid en de economie
SEM
In de sociale wetenschappen kunnen sommige constructen, zoals intelligentie, vertrouwen, motivatie, vervreemding of conservatisme, niet direct worden geobserveerd. Het zijn in essentie constructen of concepten waarvoor geen methode bestaat om ze direct te meten. Onderzoekers gebruiken hiervoor geobserveerde maten die indicatoren zijn voor een latente variabele. Structural equation modeling is een onderzoeks-raamwerk dat rekening kan houden met de meetfouten in de geobserveerde variabelen die in het model zitten. SEM is een flexibel en krachtige methode om tegelijkertijd op een goede manier de kwaliteit van het meten in de gaten te houden als om causale relaties tussen de constructen vast te stellen. In de map vind je een korte presentatie over SEM
RRStudioRmarkdown
Hier een klein boekje om jou te laten wennen aan reproduceerbaar onderzoek. Het introduceert het programma R, de RStudio-schil en de programmeertaal RMarkdown.
Bayes
Over de geschiedenis van de Bayesiaanse statistiek
Dynamische documenten maken met RMarkdown en Knitr
RMarkdown en Knitr zijn pakketten die je in staat stellen om reproduceerbare en dynamische documenten te maken. In deze blog wordt uitgelegd hoe je hiermee kunt werken.
Data exploratie
Een introductie op data exploratie aan de hand van een boek van Chester Ismay en Albert Y. Kim.

PSM
Om precies het effect van een aanpak of politieke keuze vast te stellen is een ingewikkelde kwestie. Toch is er dat soort onderzoek nodig om de keuze voor programma's te legitimeren. Tegenwoordig is er een heel spectrum van technieken om de impact van programma's vast te stellen. Dit zijn technieken die kunnen worden gebruikt binnen hele verschillende soorten impactstudies. Het is goed daar kennis van te nemen, zeker nu steeds meer mogelijk is omdat er meer data beschikbaar zijn waarop deze evaluaties gebaseerd kunnen worden. Impactstudies worden uitgevoerd om vast te stellen of programma's de effecten opleveren die ze nastreven, om te begrijpen of en waarom deze programma's werken, om vast te stellen in hoeverre veranderingen zijn toe te schrijven aan de inzet van het programma en ook om vast te stellen of de gelden op een goede manier worden besteed. Op dit terrein is er natuurlijk een enorme hoeveelheid literatuur en enkele uitgaven geven ons hiervan een goed en up-to-date overzicht^[Khandker, S.R., Koolwal, G.B. & Samad, H.A. (2010). *Handbook on Impactevaluation. Quantative Methods and Practices*. Washington D.C: The World Bank; Gertler, P.J., Martinez, S., Prenard, P., Rawlings, L.B. & Vermeersch, C.M. (2011). *Impact Evaluation in Practice*. Washington D.C.: The World Bank; Murnane, R.J. & Willet, J.B.(2011). *Methods Matter. Improving Causal Inference in Educational and Social Science Research*. New York: Oxford University]. Experimentele studies kunnen natuurlijk goede impactstudies zijn, met sterke punten en beperkingen. Maar er zijn ook aanvullende methodes die in quasi-experimentele of observationele studies kunnen worden toegepast. Zo zijn er panel datamethodes die gebruikt kunnen worden, regressie discontinu?teit methodes en instrumentele variabelen methodes. Daarnaast zijn er verschillende matchingsmethodes die in impactstudies worden gebruikt. Hier stellen we zo'n matchingsmethode voor die goed gebruikt kan worden in verschillende soorten impactstudies en laten we zien hoe deze uitgevoerd kan worden.
Tufte
De Tufte-stijl is een stijl die Edward Tufte gebruikt in zijn boeken en handouts. Tufte's stijl is bekend vanwege zijn veelvuldig gebruik van opmerkingen aan de zijkant (sidenotes), strakke integratie van zijn grafieken met tekst en zijn duidelijk gezette typografie. Deze stijl is geimplementeerd in repectievelijk LaTeX en HTML/CSS^[Zie Github repositories [tufte-latex](https://github.com/tufte-latex/tufte-latex) en [tufte-css](https://github.com/edwardtufte/tufte-css)], respectively. Beide implementaties zitten nu ook in het [**tufte** pakket](https://github.com/rstudio/tufte). Als je een LaTeX/PDF output wilt, gebruik dan `tufte_handout` format voor handouts en `tufte_book` voor boeken. Voor HTML output, gebruik je `tufte_html`. Deze formatten kunnen worden gespecificeerd in de YAML metadata aan het begin van een R Markdown-document (zie het voorbeeld hieronder), of overgebracht via de `rmarkdown::render()` functie. Zie @R-rmarkdown voor meer informatie over **rmarkdown**.
Op weg naar infografieken
Hier gaat het om een korte handleiding voor R_gebruikers die omwille van de leesbaarheid en esthetiek hun figuren in het populaire grafische design programma Illustrator willen 'oppoetsen'. Als het op visualisatie aankomt blijven de meeste R-gebruikers binnen dit programma werken. Dat is natuurlijk prima als het gaat om figuren die de analyse moeten ondersteunen en jij degene bent die er alleen naar moet kijken. Dan hoef je ook niets over de context te vermelden, niets verder uit te leggen of ervoor te zorgen dat het er allemaal mooi uitziet. Het doel dan is vooral snel figuren maken zodat je gevoel bij jouw data krijgt. R biedt je ook heel veel mogelijkheden, ook voor goede visualisatie. Echter, als het gaat om het maken van figuren die voor een breder publiek toegankelijk en leesbaar zijn en die zelf een verhaal moeten vertellen, kan het wel eens bruikbaarder en efficiënter zijn om dit R-figuur als PDF op te slaan en aanpassingen door te voeren in een vector georienteerd programma zoals Adobe Illustrator (https://www.adobe.com/nl/) of zijn open-source alternatief Inkscape (https://www.inkscape.org/nl/). Inkscape is vrij toegankelijk maar hier besteden wij enkel aandacht aan het bewerken in Adobe Illustrator.
Latex
Introductie op Latex.
Visualisatie
Hoe kun je goed werken aan datavisualisatie met ggplot2 binnen R/RStudio