Everything is related to everything else, but near things are more related than distant things (blz. 259)
Introductie

Begin dit jaar verscheen Geocomputation with R, een boek van Robin Lovelace, Jakub Nowosad en Jannes Muenchow. Het is een standaarwerk over wat vandaag de dag mogelijk is met geografische data analyse, visualisatie en modellering. Aan het boek hebben ze met z’n drieën meer dan twee jaar gewerkt en dat proces konden we gedurende die periode volgen. Ze hebben het boek open-source gemaakt en mensen uitgenodigd om te reageren op eerdere versie. Alles kon je binnenhalen en je kon als het ware meedoen aan het maken ervan. Ze hebben het met Bookdown gemaakt, ze hebben het op GitHub geplaatst en je kunt het nu nog als Git Hub-boek lezen link en alle syntaxen gebruiken. Daar wordt het ook up-to-date gehouden. Het boek en onderdelen ervan zijn reproduceerbaar, openbaar en wereldwijd toegankelijk. Recent verscheen ook een uitgave bij CRC link. Daarnaast is er ook een volle map met aanvullend materiaal link; je moet je best doen om niet om te komen in al dit materiaal.
Geocomputation with R wil iedereen helpen bij het analysere, visualiseren en modelleren van open-source geografische data. Met R heb je gereedschap in handen dat jou daartoe goed in staat stelt. Dat is eigenlijk iets van de laatste jaren. Voorheen werd dit geografische of ruimtelijke data-analyse werk met dure GIS-apparatuur uitgevoerd. Dat was enkel weggelegd voor enkele geografen die specialistische cursussen hadden gevolgd en met dure kliksytemen konden werken en voor anderen was het zeker niet te reproduceren. Maar tegenwoordig kan dit specialistische werk met een standaard laptop-computer thuis gedaan worden en Lovelace en companen laten jou heel goed zien hoe je dat moet doen. R is heel goed in moderne data-analyse en wordt door steeds meer mensen wereldwijd gebruikt. Er zijn ook andere talen waar veel mee gewerkt wordt zoals Python, Java en C++ maar de statistische capaciteiten van R kunnen hier tegenwoordig heel goed mee concurreren. R is niet alleen open-source en kosteloos, het is ook geschikt voor andere disciplines, het werkt met commando’s en syntaxen en het werk kan juist heel goed door anderen worden gereproduceerd. Anderen kunnen de resultaten van de analyses zelf genereren door gebruik te maken van toegankelijke codes. Met de term Geocomputatie onderscheiden zij zich van GIS-programma’s omdat het werk echt computerwerk is geworden, de focus ligt op het schrijven en gebruiken van codes en reproduceerbaarheid staat centraal.De laatste jaren is er niet alleen veel ontwikkeling geweest op het gebied van reproduceerbaarheid maar zijn er ook een groot aantal programma’s gekomen die het werken met ruimtelijke data mogelijk maken. R is een waar data-ecosysteem geworden met een hele sterke community van gebruikers. Lovelace et al. gaan in op de geschiedenis van die spatial pakketten waarin rgdal en sp lang de agenda hebben bepaald.Er zijn programma’s gekomen om data beter te bewerken (zoals dplyr en tidyverse) maar ook specifieke programma’s die daarop afgestemd zijn zaols sf en via dat kun je weer goed met ggplot2, plotly, raster, leaflet, sp en tmap werken. In het eerste deel van het boek leggen ze de basis, die bereiden ze in het tweede deel verder uit en in het derde deel laten ze drie concrete toepassing zien en kijken ze vooruit.
De basis
In het eerste deel van dit boek gaat in op twee fundamentele manieren om met geografische data om te gaan: vector en raster modellen. Dit zijn de twee modellen die het vak beheersen. Vector data modellen representeren de wereld door punten, lijnen en polygonen te gebruiken. Het raster model deelt de werkelijkheid in cellen van gelijke omvang in. Vector modellen worden vooral in sociale wetenschappen gebruikt en raster modellen komen we vooral in omgevingswetenschappen tegen. Tegenwoordig is sf het pakket waar verctor modellen in bewerkt worden. Het pakket is betrekkelijk nieuw en incorporeert eerdere pakketten die hiervoor gebruikelijk waren (sp, rgeos en rgdal).
sf leest en schrijft data makkelijk, het kan goede figuren maken, het behandelt de hele dataset (inclusief geografische data) als een data frame. Daarom werkt het goed met het databewerkingspakket tidyverse en de functies waarmee gewerkt worden zijn consistent en intuïtief om mee te werken. Op eenvoudige manier kun je eruit krijgen wat je wil.
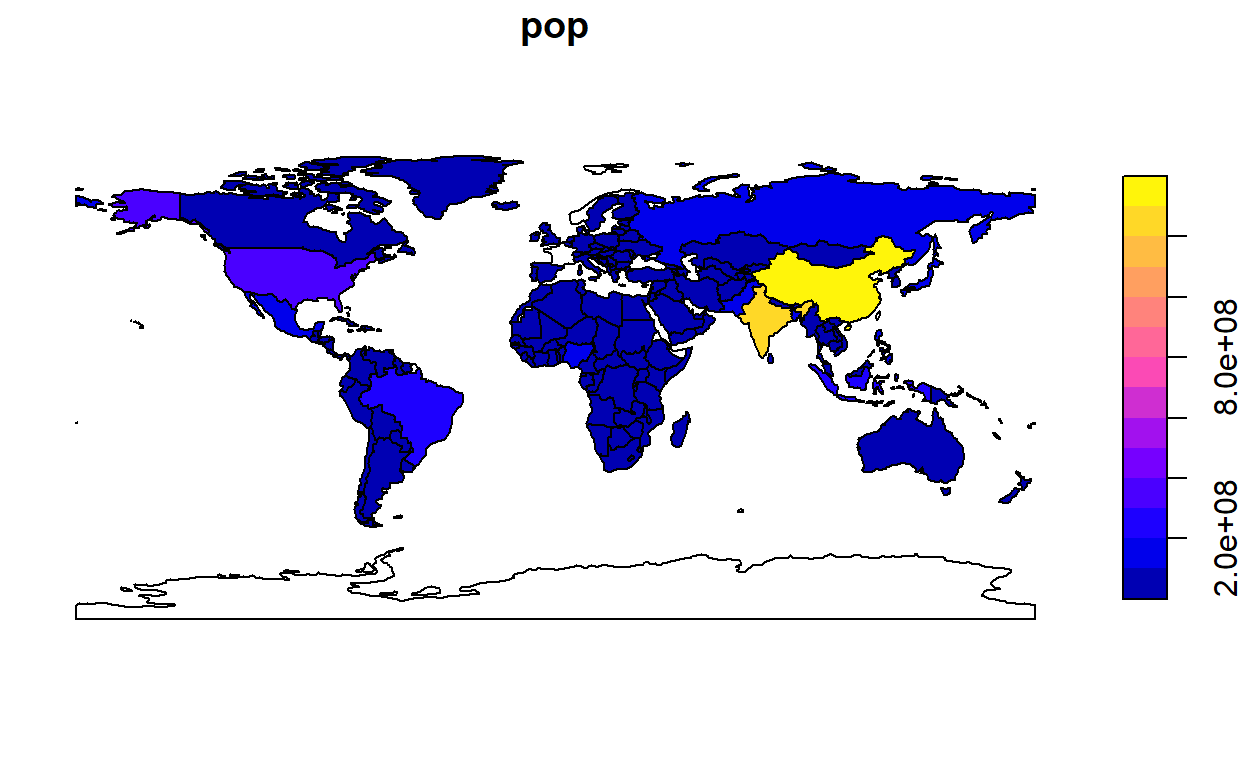
Raster modellen is de andere manier om kaarten te maken.
Voor geografische data-analyse zijn Coördinaten Referentie Systemen belangrijk waarmee 3D in 2D wordt omgezet. Kaarten kunnen er, afhankelijk van het systeem dat wordt gebruikt, anders uitzien. Lovelace en companen leggen verschillende systemen uit en ook hoe deze om te zetten zijn. Vervolgens gaan ze in op Attribute data operaties, waarbij het gaat om niet-geografische informatie die wel wel met de geografische data te maken hebben. Een bepaalde hoogte hoort bij een bepaalde ruimte, bv.. In sf zijn deze gegevens goed te verwerken en je kunt er makkelijk een subset van een dataset mee maken (uit de gegevens van de wereld kun je bijvoorbeeld de gegevens voor Europa halen of je wil alleen maar de landen afbeelden waar de gemiddelde levensverwachting groter dan 82 jaar is). Je kunt ook gegevens uit andere datasets aan een geografische dataset koppelen met sf. Een voorbeeld: de wereldgegevens gekoppeld aan koffie data:
[1] "sf" "data.frame"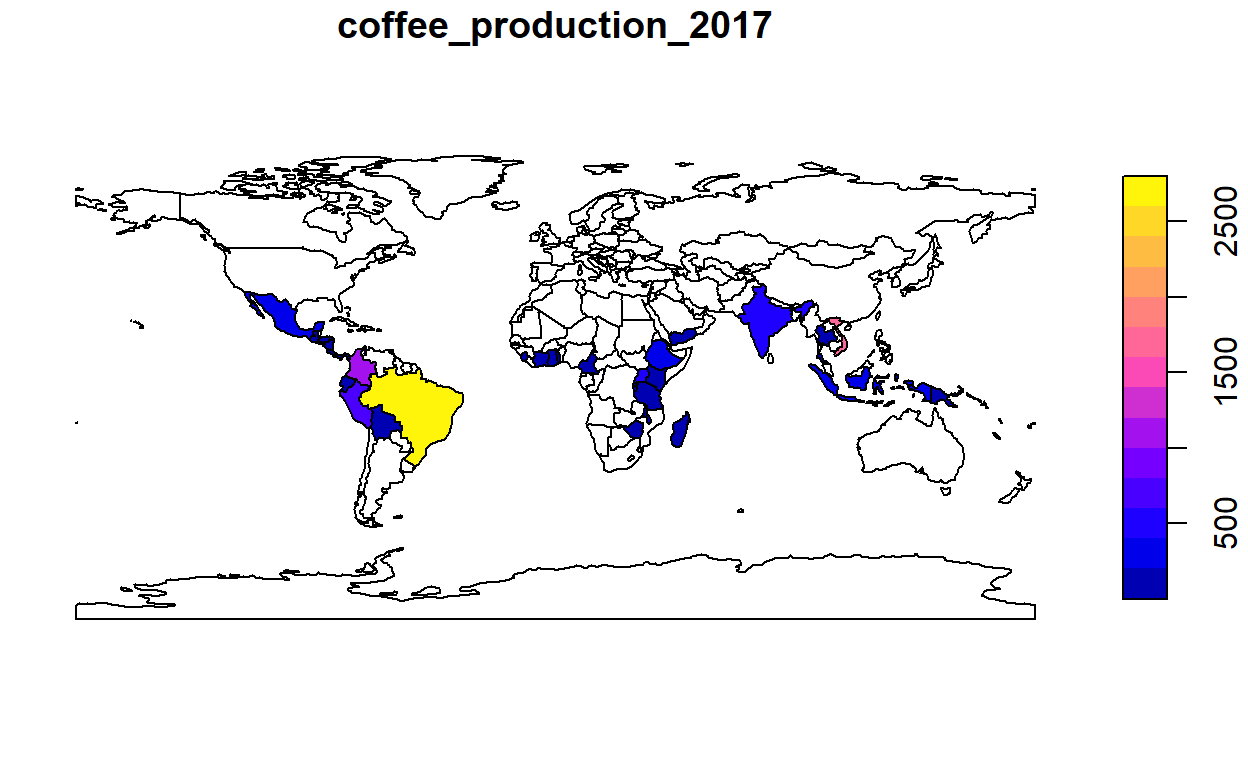
Uitbreiding
Halverwege het boek laten Lovelace et al. zien hoe je vandaag de dag goed kaarten kunt maken. Ze openen een aantal standaardpakketten
en enkele pakketten om verder te visualiseren:
Ze werken vooral met tmap omdat dat een goed visualisatiepakket is (gemaakt door de Nederlander M. Tennekes), het werkt net als sf goed met tidyverse en je kunt er statische en interactieve kaarten mee maken, in een handomdraai. Het werkt laag voor laag. Het zo opgebouwd, als we bijvoorbeeld de kaart van Nieuw Zeeland willen laten zien:
# Eerst vul je de vorm aan
tm_shape(nz) +
tm_fill()
# Dan de grenzen
tm_shape(nz) +
tm_borders()
# Dan vorm, vulling en grenzen
tm_shape(nz) +
tm_fill() +
tm_borders() 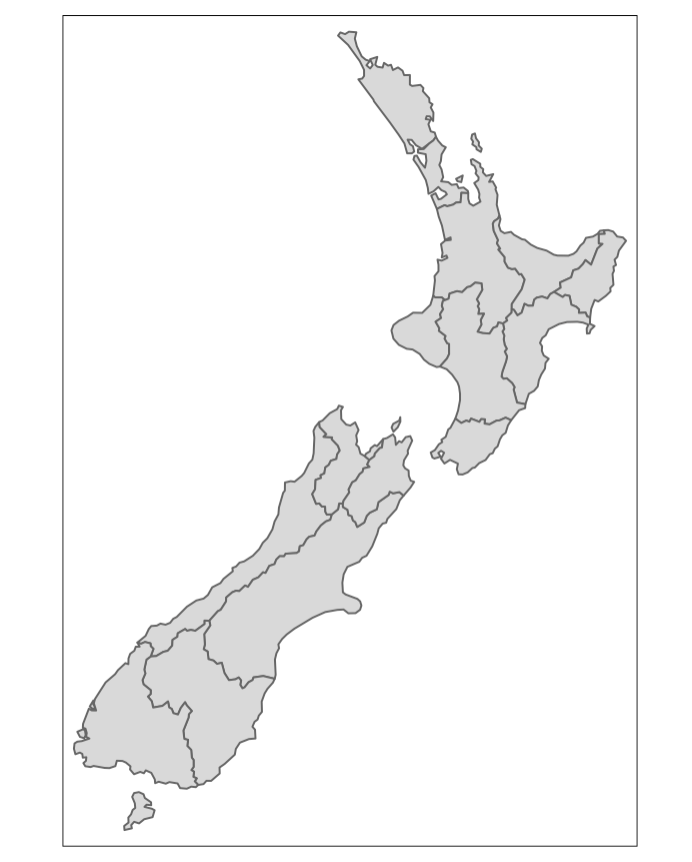
Ze laten heel veel verschillende toepassingen zien.
ma1 = tm_shape(nz) + tm_fill(col = "red")
ma2 = tm_shape(nz) + tm_fill(col = "red", alpha = 0.3)
ma3 = tm_shape(nz) + tm_borders(col = "blue")
ma4 = tm_shape(nz) + tm_borders(lwd = 3)
ma5 = tm_shape(nz) + tm_borders(lty = 2)
ma6 = tm_shape(nz) + tm_fill(col = "red", alpha = 0.3) +
tm_borders(col = "blue", lwd = 3, lty = 2)
tmap_arrange(ma1, ma2, ma3, ma4, ma5, ma6)
Ze gaan in dit hoofdstuk in op allerlei aspecten van het kaarten maken: de objecten zelf, de esthetica, de kleur, de lay-out en ook om verschillende kaarten naast elkaar te kunnen plaatsen (bv van 1970, 1990, 2010 en 2030).
urb_1970_2030 = urban_agglomerations %>%
filter(year %in% c(1970, 1990, 2010, 2030))
tm_shape(world) +
tm_polygons() +
tm_shape(urb_1970_2030) +
tm_symbols(col = "black", border.col = "white", size = "population_millions") +
tm_facets(by = "year", nrow = 2, free.coords = FALSE)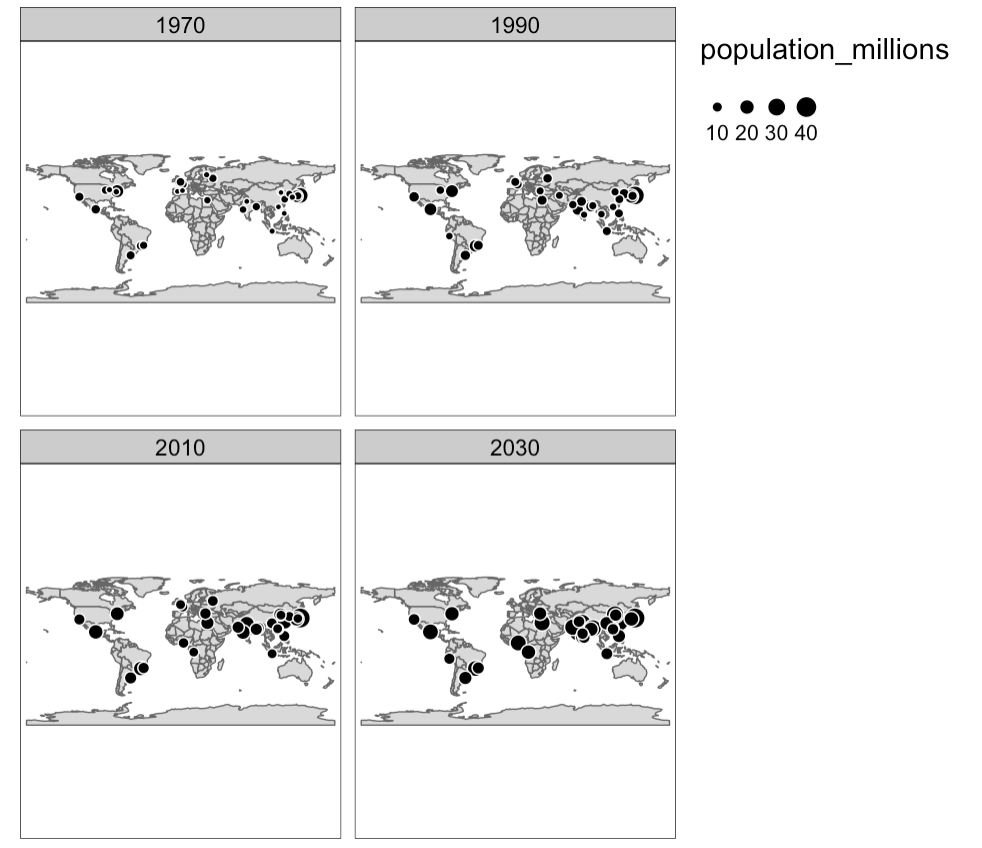
Ze laten ook zien hoe je animaties kunt maken, interactieve kaarten en hoe je met andere pakketten kaarten kunt maken (mapview, leaflet, plotly, ggplot). Dit is een belangrijk hoofdstuk om zelf door te nemen met jouw computer op jouw schoot zoals ik dat nu heb. Een apart hoofdstuk besteden ze aan de relaties met andere GIS-pakketten. Omdat ik daar niet mee werk, laat ik dit voor hier liggen. Je hoeft niet alleen anderen te volgen in wat zij hebben gedaan maar je kunt ook jouw eigen scripts en algoritmes schrijven en de Lovelace et al. nodigen je daarvoor uit. Hoofstuk 11 gaat in op statistisch leren en machine learning. Ze geven een voorbeeld van supervised en unsupervised leren, verdelen de dataset in een training en een testset en volgen met het pakket mlr een aantal standaard stappen om te kunnen voorspellen. Het boek laat je de toekomst proeven.
Tot slot
In de laatste hoofdstukken hebben de drie schrijvers elk een hoofdstuk genomen om te laten zien hoe geocomputation op hun vakgebied is te gebruiken. Lovelace heeft het hoofdstuk over Transport geschreven en werkt een case study van Bristol uit.

Novosad werkt het onderwerp Geomarketing uit aan de hand van een studie over fietswinkels in Duitsland.

Muenchov werkt tot slot een ecologisch studie onderwerp in Peru uit
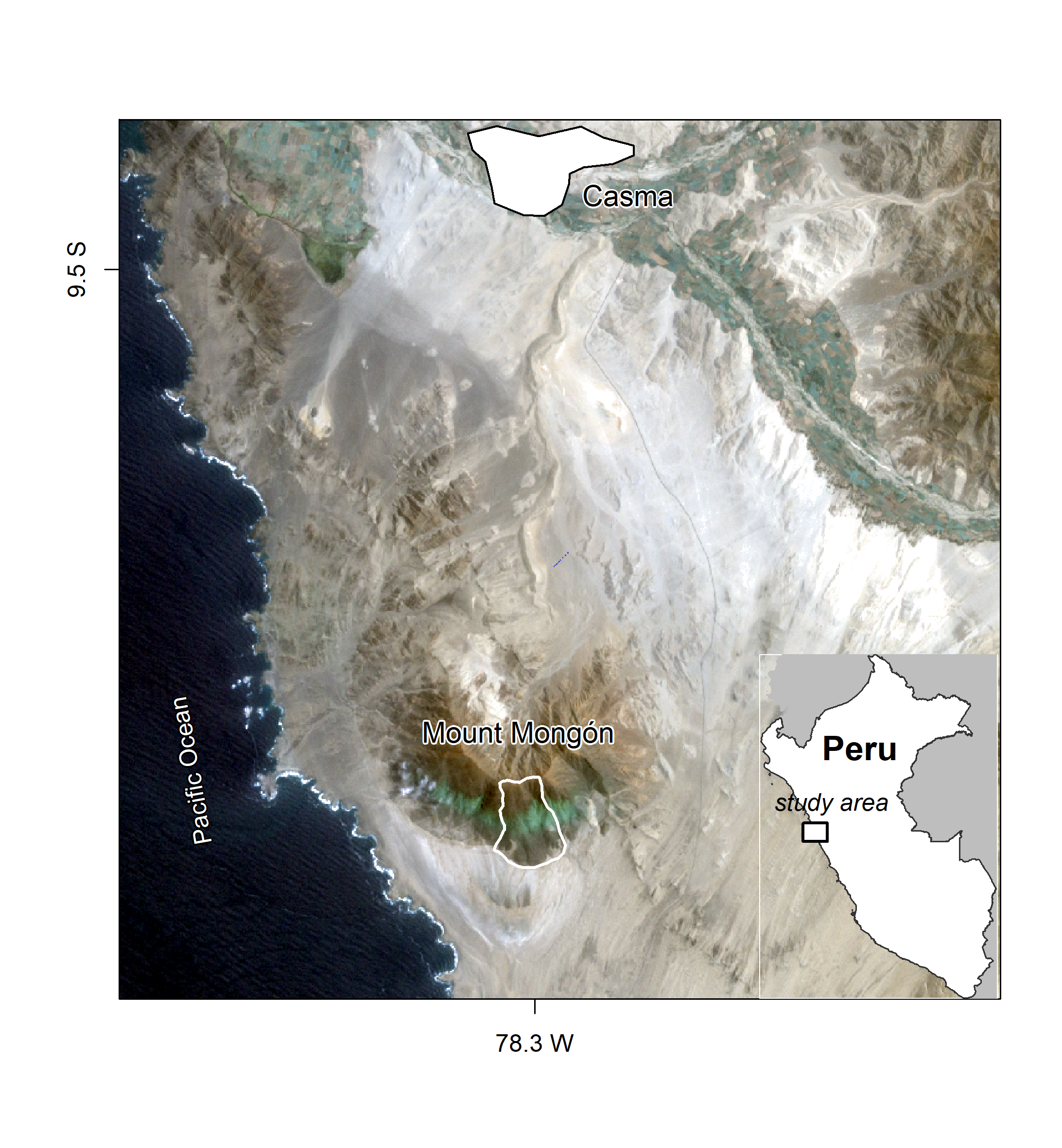
Het laatste hoofdstuk is een concluderend hoofdstuk waarin ze vaststellen dat de manier waarop ze met sf en tidyverse in dit boek de ruimtelijke data benaderen een manier is om met de werkelijkheid om te gaan. Veel van wat ze hier presenteren kan ook met sp en rdal bereikt worden zoals de afgelopen jaren gebruikelijk. Deze nieuwe manier, hun manier, zal zich de komende jaren verder ontwikkelen. De keus van de pakketten is aan de gebruiker. Dit boek is de basis van geocomputation en veel wordt ook niet in het boek besproken. Daarvan zijn ze zich bewust, of het nu om big data gaat of andere analysetechnieken. Hierover is elders meer te vinden. Maar met hun kennis in de achterzak kom je wel verder in het eigen maken van deze andere technieken, kun je meer ontdekken en ook meer daarvan leren. Hun boek, en daarom vind ik het ook zo goed, toont vooral hoe een open-source benadering kan werken. Het leert je creatief met data omgaan, je leert echte problemen op te lossen, gebruik te maken van goede wetenschappelijke tools en het leert je kennis te delen en te reproduceren. Het daagt je uit verder te kijken, voort te bouwen op wat anderen hebben gedaan en alles praktisch toe te passen. Het daagt je uit hier zelf mee aan de slag te gaan en daarin samen te werken met anderen.
Eerder had ik de html-versie gelezen en afgelopen weken heb ik met veel plezier dit boek gelezen, een groot aantal presentaties van Lovelace op YouTube bekeken en enkele powerpoint presentaties bekeken. Ik heb verschillende syntaxen geprobeerd en ik kan je zeggen: deze schrijvers helpen je echt om bij de tijd te blijven en achgterstand in te halen. Het plezier en het gemak straalt er vanaf. Het is stimulerend en het zijn geen nerds. Ze hebben wat te vertellen en willen dat deze ontwikkelingen ons verder helpen. Geocomputation with R; het is een fantastisch boek.
Boek: Lovelace,R., Nowosad, J.& Muenchow, J. (2019). Geocomputation with R. London: Chapman & Hall. 353 p.