Laad tidyverse, tidymodels en enkele andere pakketten en zet theme (optioneel) voor een bepaalde vormgeving van de figuren.
Lees de King County Housing-data in en kijk eens naar de eerste vijf rijen.
# A tibble: 5 x 21
id date price bedrooms bathrooms sqft_living sqft_lot
<chr> <date> <dbl> <int> <dbl> <int> <int>
1 7129300520 2014-10-13 221900 3 1 1180 5650
2 6414100192 2014-12-09 538000 3 2.25 2570 7242
3 5631500400 2015-02-25 180000 2 1 770 10000
4 2487200875 2014-12-09 604000 4 3 1960 5000
5 1954400510 2015-02-18 510000 3 2 1680 8080
# … with 14 more variables: floors <dbl>, waterfront <lgl>,
# view <int>, condition <fct>, grade <fct>, sqft_above <int>,
# sqft_basement <int>, yr_built <int>, yr_renovated <int>,
# zipcode <fct>, lat <dbl>, long <dbl>, sqft_living15 <int>,
# sqft_lot15 <int>Over de house_prices data lezen we het volgende:
“Deze dataset bevat huizenverkoopprijzen voor King County, waar Seattle deel van uitmaakt. Het omvat huizen verkocht tussen mei 2014 en mei 2015. Deze dataset is verkregen via Kaggle.com.” De beschrijving van de variabelen in de dataset in de documentatie lijkt niet helemaal te kloppen. Een meer accurate beschrijving is hieronder te vinden. In ieder geval willen we hier de prijs van woningen modelleren.
Exploratie
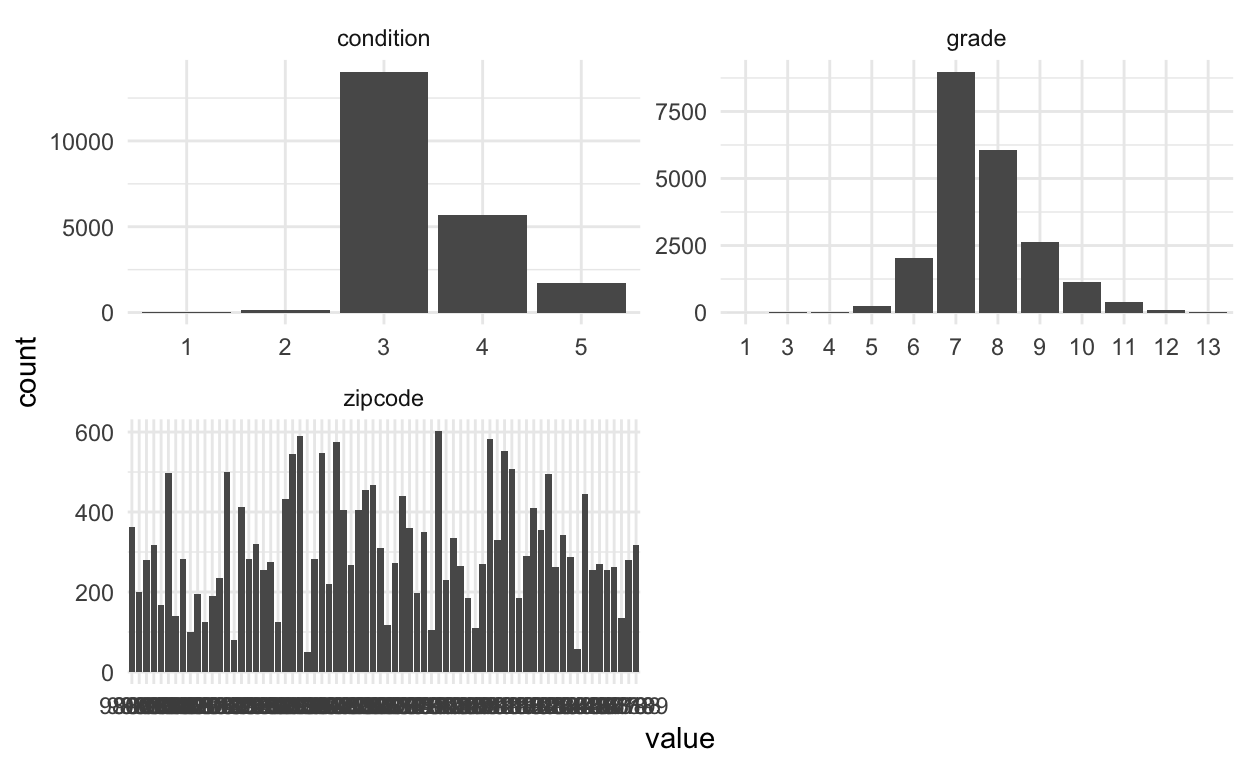
Kijk eerst eens naar de verdelingen van alle variabelen om te zien of er iets onregelmatigs aan de hand is.
Kwantitatieve variabelen:

Dingen die opvielen en eerste gedachten over het opstartproces: * ‘Right-skewness’ in de variabele price en alle variabelen betreffende vierkante meters –> log transformeren indien lineaire regressie wordt gebruikt. * Veel 0’s in sqft_basement, view, en yr_renovated –> maak indicator variabelen van het hebben van dat kenmerk vs. niet hebben , dat wil zeggen een variabele genaamd basement waar een 0 aangeeft geen kelder (sqft_basement = 0) en wel een kelder bij (sqft_basement > 0).
* Leeftijd van huis is misschien een betere, interpreteerbare variabele dan bouwjaar –> age_at_sale = year(date) - yr_built.
Data splitsen (in train- en test-sets)
Eerst splitsen we de gegevens op in training- en test-datasets. We gebruiken de trainingsgegevens om verschillende soorten modellen te proberen en de parameters van die modellen zo nodig aan te passen. De testdataset wordt bewaard voor het allerlaatst om een kleine subset van modellen te vergelijken. De initial_split() functie uit de rsample bibliotheek (onderdeel van tidymodels) wordt gebruikt om tot deze splitsing te komen. We splitsen deze dataset random, maar er zijn andere mogelijkheden om tot gestratificeerde steekproeven te komen. Daarna gebruiken we training() en testing() om de twee datasets, house_training en house_testing, te extraheren.
<Analysis/Assess/Total>
<16210/5403/21613>Later zullen we 5-voudige cross-validatie gebruiken om het model te evalueren en de modelparameters aan te passen. We zetten de vijfvoud van de trainingsdata op met de vfold_cv() functie. We zullen dit later in meer detail uitleggen.
Data voorspel: recipe() en step_xxx()
We gebruiken de
recipe()-functie om de uitkomstvariabele en de predictoren te definiëren.Een verscheidenheid van
step_xxx()functies kan worden gebruikt om data te bewerken/transformeren. Vind ze allemaal hier. Ik heb er een paar gebruikt, met korte beschrijvingen in de code. Ik heb ook een aantal selectiefuncties gebruikt, zoalsall_predictors()enall_nominal()om de juiste variabelen te selecteren.We gebruiken ook
update_roles()om de rollen van sommige variabelen te veranderen. Voor ons zijn dit variabelen die we misschien willen meenemen voor evaluatiedoeleinden, maar die niet gebruikt zullen worden bij het bouwen van het model. Ik heb gekozen voor de rolevaluative, maar je kunt die rol elke naam geven die je maar wilt, bijvoorbeeldid,extra,junk(misschien een slecht idee?).
Pas het toe op de trainings-dataset, gewoon om te zien wat er gebeurt. Let op de namen van de variabelen.
# A tibble: 16,210 x 36
id date bedrooms bathrooms sqft_living sqft_lot floors
<fct> <date> <int> <dbl> <dbl> <dbl> <dbl>
1 71293005… 2014-10-13 3 1 3.07 3.75 1
2 64141001… 2014-12-09 3 2.25 3.41 3.86 2
3 56315004… 2015-02-25 2 1 2.89 4 1
4 24872008… 2014-12-09 4 3 3.29 3.70 1
5 19544005… 2015-02-18 3 2 3.23 3.91 1
6 72375503… 2014-05-12 4 4.5 3.73 5.01 1
7 13214000… 2014-06-27 3 2.25 3.23 3.83 2
8 20080002… 2015-01-15 3 1.5 3.03 3.99 1
9 24146001… 2015-04-15 3 1 3.25 3.87 1
10 37935001… 2015-03-12 3 2.5 3.28 3.82 2
# … with 16,200 more rows, and 29 more variables: waterfront <dbl>,
# view <dbl>, sqft_above <dbl>, zipcode <fct>, lat <dbl>,
# long <dbl>, price <dbl>, basement <dbl>, renovated <dbl>,
# age_at_sale <dbl>, condition_X2 <dbl>, condition_X3 <dbl>,
# condition_X4 <dbl>, condition_X5 <dbl>, grade_X7 <dbl>,
# grade_X8 <dbl>, grade_X9 <dbl>, grade_high <dbl>,
# date_month_Feb <dbl>, date_month_Mar <dbl>, date_month_Apr <dbl>,
# date_month_May <dbl>, date_month_Jun <dbl>, date_month_Jul <dbl>,
# date_month_Aug <dbl>, date_month_Sep <dbl>, date_month_Oct <dbl>,
# date_month_Nov <dbl>, date_month_Dec <dbl>Het model definiëren en workflows creëren
Nu we de gegevens hebben opgesplitst en voorbewerkt, zijn we klaar om te modelleren! Eerst zullen we price (die nu eigenlijk log(price) is) modelleren met eenvoudige lineaire regressie.
We zullen dit doen met behulp van enkele modelleringsfuncties uit het parsnip pakket. Vind alle beschikbare functies hier. Hier is lineaire regressie meer in detail.
Om ons model te definiëren, moeten we de volgende stappen zetten:
- Bepaal het modeltype, dat is het algemene moeltype dat u wilt draaien.
- Stel de motor in, die het pakket/de functie bepaalt die zal worden gebruikt om het model te draaien.
- Stel de modus in, die ofwel “regressie” is voor continue uitkomstvariabelen of “classificatie” voor binaire/categorische uitkomstvariabelen. (Merk op dat voor lineaire regressie, het alleen “regressie” kan zijn, dus we hebben deze stap in dit geval niet NODIG).
- (OPTIONEEL) Stel argumenten in om af te stemmen (‘tunen’). We zullen hier later een voorbeeld van zien.
Dit is slechts het opzetten van het proces. We hebben het model nog niet aan de gegevens aangepast en er is nog één stap voordat we dat doen - een workflow maken! Hier wordt de voorbewerking en de stappen in het model gecombineerd.
══ Workflow ══════════════════════════════════════════════════════════
Preprocessor: Recipe
Model: linear_reg()
── Preprocessor ──────────────────────────────────────────────────────
6 Recipe Steps
● step_rm()
● step_log()
● step_mutate()
● step_rm()
● step_date()
● step_dummy()
── Model ─────────────────────────────────────────────────────────────
Linear Regression Model Specification (regression)
Computational engine: lm Modelleren en evalueren
Nu zijn we eindelijk klaar om het model te draaien! Na al dat werk, lijkt dit deel eenvoudig. We gebruiken eerst de fit() functie om het model te fitten, door te vertellen op welke dataset we het model willen draaien. Daarna gebruiken we enkele andere functies om de resultaten mooi weer te geven.
# A tibble: 31 x 5
term estimate std.error statistic p.value
<chr> <dbl> <dbl> <dbl> <dbl>
1 (Intercept) 4.01 0.048 83.4 0
2 bedrooms -0.018 0.002 -11.2 0
3 bathrooms 0.036 0.003 14.3 0
4 sqft_living 0.294 0.025 11.7 0
5 sqft_lot -0.038 0.003 -11.0 0
6 floors 0.021 0.003 6.87 0
7 waterfront 0.194 0.013 15.0 0
8 view -0.061 0.004 -15.6 0
9 sqft_above 0.149 0.025 5.99 0
10 basement -0.042 0.005 -9.14 0
# … with 21 more rowsOm het model te evalueren, gebruiken we crossvalidatie (CV), specifiek de 5-voudige CV. (Ik veronderstel dat we niet zowel de vorige stap van het passen van een model op de trainingsgegevens EN deze stap moeten doen, maar ik kon er niet achter komen hoe we het uiteindelijke model uit de CV-gegevens kunnen halen … dus dit was mijn oplossing voor nu). We passen het model dus aan met de 5-voudige dataset die we in het begin hebben gemaakt. Voor een diepere discussie over crossvalidatie, raad ik Bradley Boehmke’s Resampling sectie van Hands on Machine Learning with R aan.
# A tibble: 10 x 5
id .metric .estimator .estimate .config
<chr> <chr> <chr> <dbl> <chr>
1 Fold1 rmse standard 0.135 Preprocessor1_Model1
2 Fold1 rsq standard 0.662 Preprocessor1_Model1
3 Fold2 rmse standard 0.137 Preprocessor1_Model1
4 Fold2 rsq standard 0.644 Preprocessor1_Model1
5 Fold3 rmse standard 0.137 Preprocessor1_Model1
6 Fold3 rsq standard 0.638 Preprocessor1_Model1
7 Fold4 rmse standard 0.133 Preprocessor1_Model1
8 Fold4 rsq standard 0.655 Preprocessor1_Model1
9 Fold5 rmse standard 0.135 Preprocessor1_Model1
10 Fold5 rsq standard 0.642 Preprocessor1_Model1# A tibble: 2 x 6
.metric .estimator mean n std_err .config
<chr> <chr> <dbl> <int> <dbl> <chr>
1 rmse standard 0.135 5 0.000668 Preprocessor1_Model1
2 rsq standard 0.648 5 0.00437 Preprocessor1_Model1# A tibble: 2 x 5
# Groups: .metric [2]
.metric .estimator mean n std_err
<chr> <chr> <dbl> <int> <dbl>
1 rmse standard 0.135 5 0.000668
2 rsq standard 0.648 5 0.00437 Voorspellen en evalueren van testgegevens
In dit eenvoudige scenario zijn we wellicht geïnteresseerd in hoe het model presteert op de testgegevens die werden weggelaten. De onderstaande code past het model toe op de trainingsgegevens en past het toe op de testgegevens. Er zijn andere manieren waarop we dit hadden kunnen doen, maar de manier waarop we het hier doen zal nuttig zijn wanneer we complexere modellen gaan gebruiken waarbij we de modelparameters moeten afstellen.
Nadat het model is aangepast en toegepast, verzamelen we de prestatiecijfers en geven we ze weer en tonen we de voorspellingen van de testgegevens.
# A tibble: 2 x 4
.metric .estimator .estimate .config
<chr> <chr> <dbl> <chr>
1 rmse standard 0.135 Preprocessor1_Model1
2 rsq standard 0.655 Preprocessor1_Model1# A tibble: 5,403 x 5
id .pred .row price .config
<chr> <dbl> <int> <dbl> <chr>
1 train/test split 5.58 12 5.67 Preprocessor1_Model1
2 train/test split 5.53 17 5.60 Preprocessor1_Model1
3 train/test split 5.90 27 5.97 Preprocessor1_Model1
4 train/test split 5.58 29 5.64 Preprocessor1_Model1
5 train/test split 5.67 31 5.76 Preprocessor1_Model1
6 train/test split 5.88 38 5.81 Preprocessor1_Model1
7 train/test split 5.69 40 5.78 Preprocessor1_Model1
8 train/test split 5.79 41 5.80 Preprocessor1_Model1
9 train/test split 5.77 42 5.89 Preprocessor1_Model1
10 train/test split 5.66 44 5.84 Preprocessor1_Model1
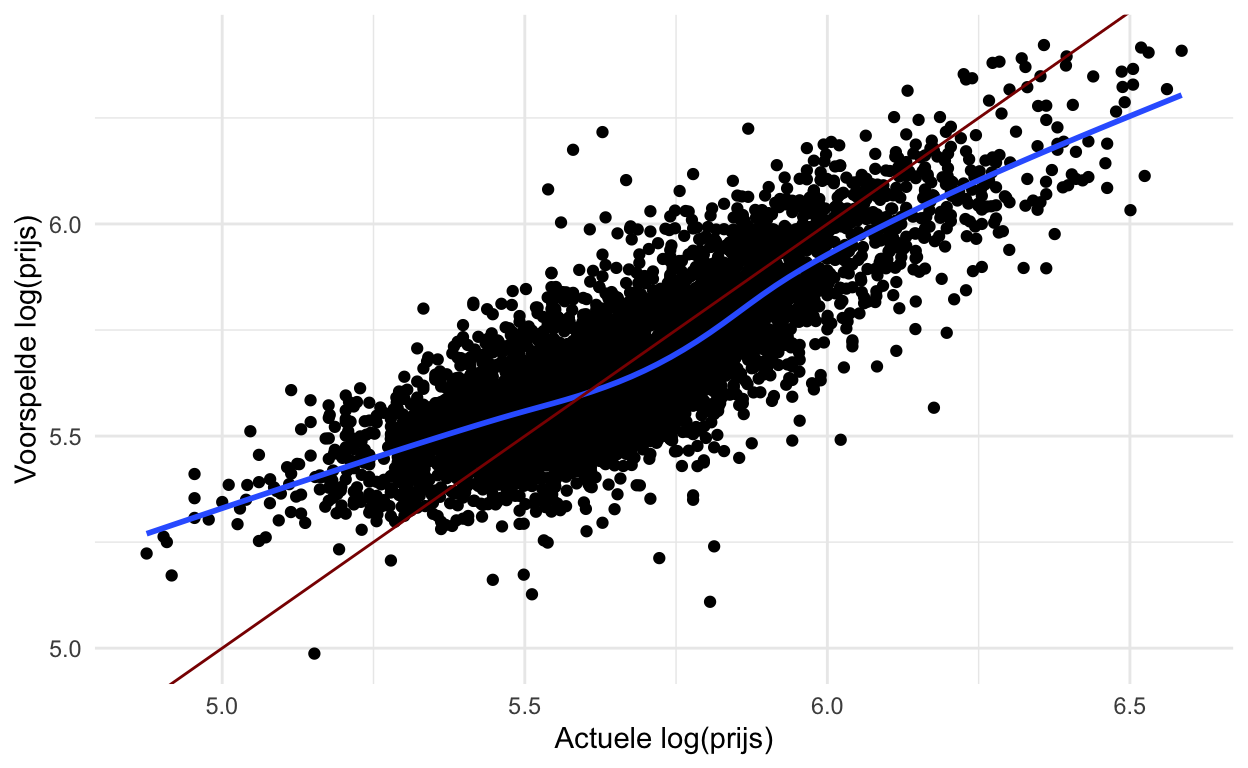
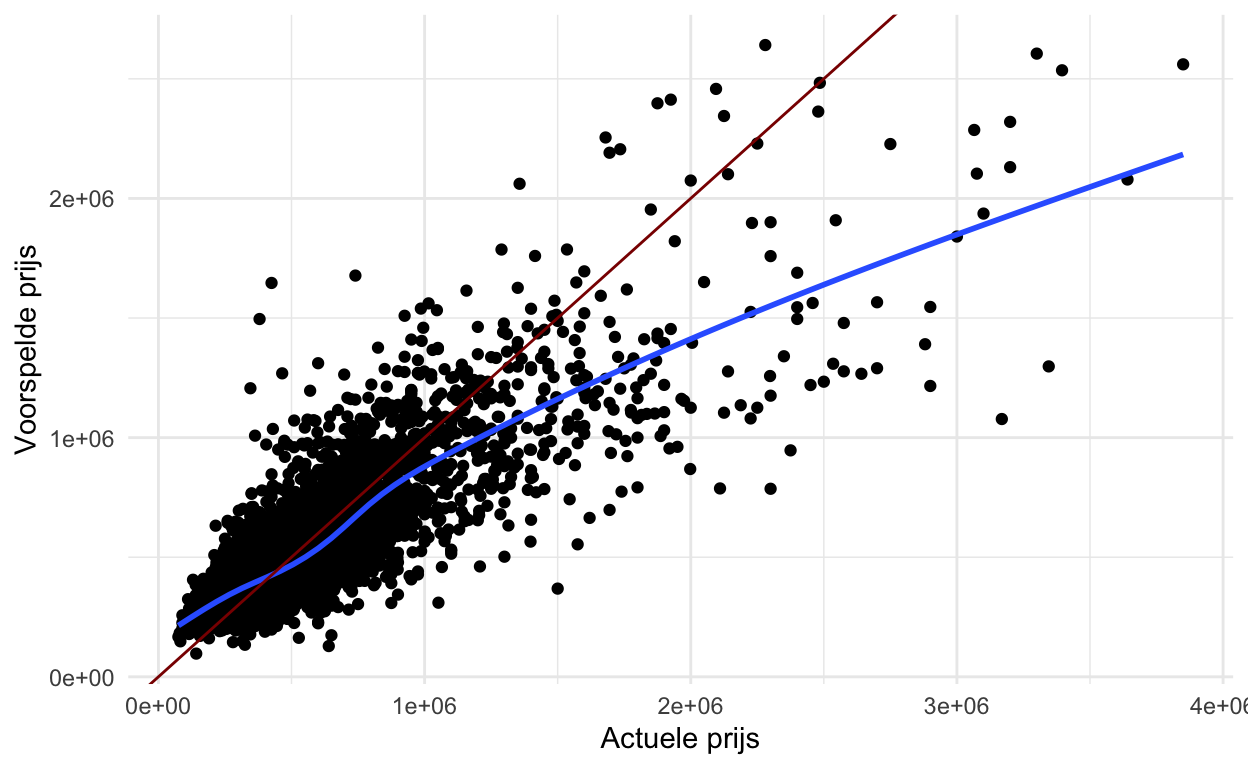
# … with 5,393 more rowsDe onderstaande code maakt een eenvoudige plot om de voorspelde vs. de werkelijke prijs van de huisgegevens te onderzoeken.
Hoe zal het model worden gebruikt?
Wanneer we modellen creëren is het belangrijk na te denken over hoe het model zal worden gebruikt en met name hoe het model schade zou kunnen berokkenen. Wat opvalt in de bovenstaande grafieken is dat de prijs van woningen met een lagere prijs gemiddeld wordt overschat, terwijl de prijs van woningen met een hogere prijs gemiddeld wordt onderschat.
Wat als dit model werd gebruikt om de prijs van woningen te bepalen voor de onroerendgoedbelasting? Dan zouden lager geprijsde huizen te zwaar worden belast en hoger geprijsde huizen te weinig.
Mer complexe modellen met tuning parameters
Nu gaan we de Least Absolute Shrinkage and Selection Operator (LASSO) regressie proberen. Deze methode krimpt sommige coëfficiënten tot 0 op basis van een strafterm. We zullen crossvalidatie gebruiken om ons te helpen de beste strafterm te vinden.
Het model opzetten
We zetten het model op zoals we het lineaire model hebben opgezet, maar voegen nu een set_args() functie toe. We vertellen het model dat we de penalty parameter later gaan aanpassen.
De workflow updaten
En dan creëren we een LASSO workflow.
══ Workflow ══════════════════════════════════════════════════════════
Preprocessor: Recipe
Model: linear_reg()
── Preprocessor ──────────────────────────────────────────────────────
6 Recipe Steps
● step_rm()
● step_log()
● step_mutate()
● step_rm()
● step_date()
● step_dummy()
── Model ─────────────────────────────────────────────────────────────
Linear Regression Model Specification (regression)
Main Arguments:
penalty = tune()
mixture = 1
Computational engine: glmnet Afstemmen van de strafparameter
We gebruiken de grid_regular() functie uit de dials bibliotheek om een aantal waarden van de penalty parameter voor ons te kiezen. Als alternatief kunnen we ook een vector van waarden opgeven die we willen proberen.
# A tibble: 20 x 1
penalty
<dbl>
1 1.00e-10
2 3.36e-10
3 1.13e- 9
4 3.79e- 9
5 1.27e- 8
6 4.28e- 8
7 1.44e- 7
8 4.83e- 7
9 1.62e- 6
10 5.46e- 6
11 1.83e- 5
12 6.16e- 5
13 2.07e- 4
14 6.95e- 4
15 2.34e- 3
16 7.85e- 3
17 2.64e- 2
18 8.86e- 2
19 2.98e- 1
20 1.00e+ 0Gebruik de tune_grid() functie om het model te draaien met behulp van crossvalidatie voor alle penalty_grid waarden en evalueer op alle vouwen.
# Tuning results
# 5-fold cross-validation
# A tibble: 5 x 4
splits id .metrics .notes
<list> <chr> <list> <list>
1 <rsplit [12968/3242]> Fold1 <tibble [40 × 5]> <tibble [2 × 1]>
2 <rsplit [12968/3242]> Fold2 <tibble [40 × 5]> <tibble [2 × 1]>
3 <rsplit [12968/3242]> Fold3 <tibble [40 × 5]> <tibble [2 × 1]>
4 <rsplit [12968/3242]> Fold4 <tibble [40 × 5]> <tibble [2 × 1]>
5 <rsplit [12968/3242]> Fold5 <tibble [40 × 5]> <tibble [2 × 1]>Bekijk de resultaten van de cross-validatie.
# A tibble: 100 x 6
id penalty .metric .estimator .estimate .config
<chr> <dbl> <chr> <chr> <dbl> <chr>
1 Fold1 1.00e-10 rmse standard 0.135 Preprocessor1_Model01
2 Fold1 3.36e-10 rmse standard 0.135 Preprocessor1_Model02
3 Fold1 1.13e- 9 rmse standard 0.135 Preprocessor1_Model03
4 Fold1 3.79e- 9 rmse standard 0.135 Preprocessor1_Model04
5 Fold1 1.27e- 8 rmse standard 0.135 Preprocessor1_Model05
6 Fold1 4.28e- 8 rmse standard 0.135 Preprocessor1_Model06
7 Fold1 1.44e- 7 rmse standard 0.135 Preprocessor1_Model07
8 Fold1 4.83e- 7 rmse standard 0.135 Preprocessor1_Model08
9 Fold1 1.62e- 6 rmse standard 0.135 Preprocessor1_Model09
10 Fold1 5.46e- 6 rmse standard 0.135 Preprocessor1_Model10
# … with 90 more rows# A tibble: 20 x 7
penalty .metric .estimator mean n std_err .config
<dbl> <chr> <chr> <dbl> <int> <dbl> <chr>
1 1.00e-10 rmse standard 0.135 5 0.000644 Preprocessor1_Mod…
2 3.36e-10 rmse standard 0.135 5 0.000644 Preprocessor1_Mod…
3 1.13e- 9 rmse standard 0.135 5 0.000644 Preprocessor1_Mod…
4 3.79e- 9 rmse standard 0.135 5 0.000644 Preprocessor1_Mod…
5 1.27e- 8 rmse standard 0.135 5 0.000644 Preprocessor1_Mod…
6 4.28e- 8 rmse standard 0.135 5 0.000644 Preprocessor1_Mod…
7 1.44e- 7 rmse standard 0.135 5 0.000644 Preprocessor1_Mod…
8 4.83e- 7 rmse standard 0.135 5 0.000644 Preprocessor1_Mod…
9 1.62e- 6 rmse standard 0.135 5 0.000644 Preprocessor1_Mod…
10 5.46e- 6 rmse standard 0.135 5 0.000644 Preprocessor1_Mod…
11 1.83e- 5 rmse standard 0.135 5 0.000644 Preprocessor1_Mod…
12 6.16e- 5 rmse standard 0.135 5 0.000640 Preprocessor1_Mod…
13 2.07e- 4 rmse standard 0.135 5 0.000623 Preprocessor1_Mod…
14 6.95e- 4 rmse standard 0.135 5 0.000591 Preprocessor1_Mod…
15 2.34e- 3 rmse standard 0.136 5 0.000522 Preprocessor1_Mod…
16 7.85e- 3 rmse standard 0.142 5 0.000513 Preprocessor1_Mod…
17 2.64e- 2 rmse standard 0.161 5 0.000515 Preprocessor1_Mod…
18 8.86e- 2 rmse standard 0.191 5 0.000896 Preprocessor1_Mod…
19 2.98e- 1 rmse standard 0.228 5 0.000960 Preprocessor1_Mod…
20 1.00e+ 0 rmse standard 0.228 5 0.000960 Preprocessor1_Mod…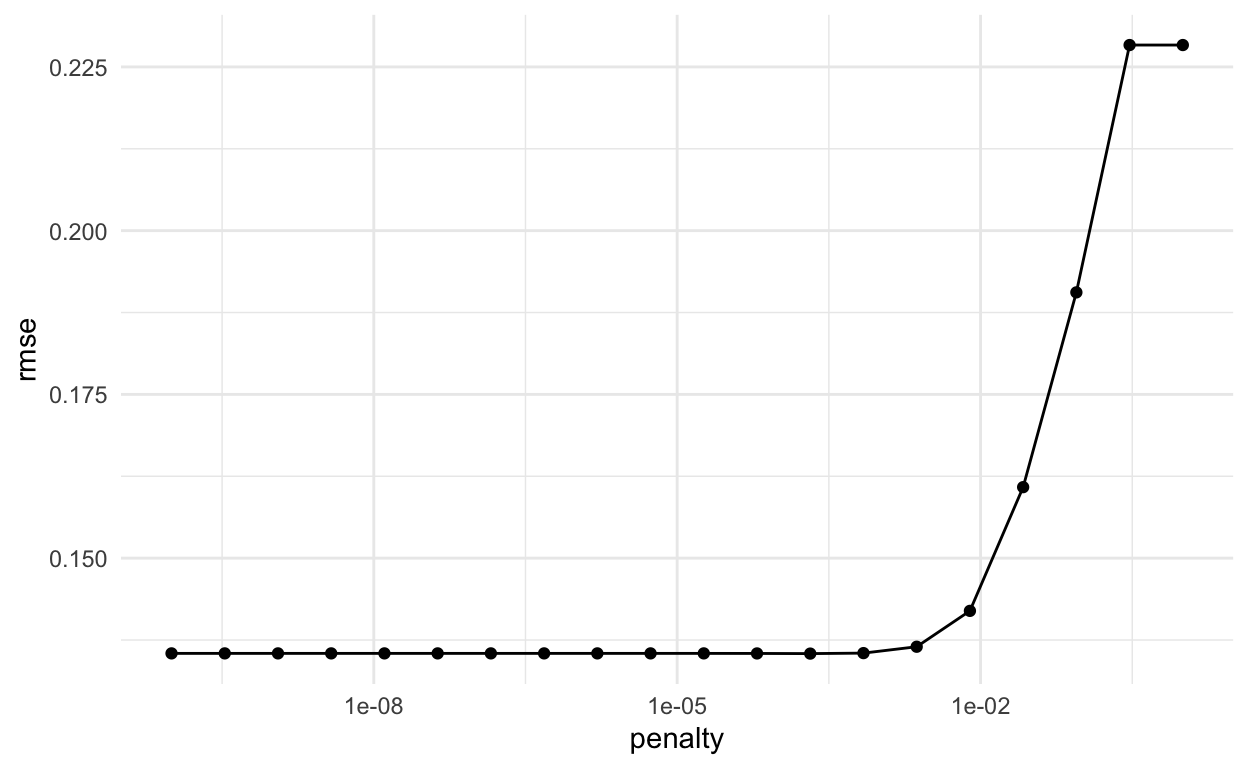
# A tibble: 1 x 2
penalty .config
<dbl> <chr>
1 0.000207 Preprocessor1_Model13Update de workflow voor best afgestemde parameter
Pas de workflow aan om de beste afstemparameter (kleinste rmse, met select_best() in vorige stap) in het model op te nemen. Er zijn andere manieren om modellen te selecteren, zoals select_by_one_std_error() die “het meest eenvoudige model selecteert dat binnen één standaardfout van de numeriek optimale resultaten ligt”.
══ Workflow ══════════════════════════════════════════════════════════
Preprocessor: Recipe
Model: linear_reg()
── Preprocessor ──────────────────────────────────────────────────────
6 Recipe Steps
● step_rm()
● step_log()
● step_mutate()
● step_rm()
● step_date()
● step_dummy()
── Model ─────────────────────────────────────────────────────────────
Linear Regression Model Specification (regression)
Main Arguments:
penalty = 0.000206913808111479
mixture = 1
Computational engine: glmnet Pas de beste afstelling toe op de trainingsgegevens
Nu kunnen we dit toepassen op de trainingsgegevens en het resulterende model bekijken. De uitvoer van het model was niet wat ik verwachtte. Volgens Julia Silge’s antwoord op mijn vraag hier, zou dit verholpen moeten zijn als je parsnip installeert vanaf GitHub] met devtools::install_github("tidymodels/parsnip") van de devtools bibliotheek.
══ Workflow [trained] ════════════════════════════════════════════════
Preprocessor: Recipe
Model: linear_reg()
── Preprocessor ──────────────────────────────────────────────────────
6 Recipe Steps
● step_rm()
● step_log()
● step_mutate()
● step_rm()
● step_date()
● step_dummy()
── Model ─────────────────────────────────────────────────────────────
Call: glmnet::glmnet(x = maybe_matrix(x), y = y, family = "gaussian", alpha = ~1)
Df %Dev Lambda
1 0 0.00 0.153800
2 1 7.71 0.140200
3 1 14.11 0.127700
4 1 19.42 0.116400
5 1 23.83 0.106000
6 1 27.49 0.096610
7 1 30.53 0.088030
8 1 33.06 0.080210
9 1 35.15 0.073080
10 2 37.42 0.066590
11 2 39.41 0.060670
12 2 41.06 0.055280
13 2 42.43 0.050370
14 3 43.93 0.045900
15 3 45.24 0.041820
16 3 46.32 0.038100
17 4 47.48 0.034720
18 5 48.59 0.031640
19 6 49.53 0.028830
20 7 50.48 0.026260
21 7 51.84 0.023930
22 8 52.98 0.021810
23 8 54.00 0.019870
24 9 54.93 0.018100
25 11 56.10 0.016490
26 10 57.40 0.015030
27 11 58.29 0.013690
28 11 59.06 0.012480
29 12 59.70 0.011370
30 12 60.25 0.010360
31 13 60.71 0.009439
32 13 61.10 0.008600
33 13 61.43 0.007836
34 13 61.71 0.007140
35 14 61.95 0.006506
36 15 62.18 0.005928
37 15 62.40 0.005401
38 16 62.57 0.004921
39 17 62.96 0.004484
40 18 63.28 0.004086
41 18 63.56 0.003723
42 20 63.80 0.003392
43 20 64.00 0.003091
44 20 64.16 0.002816
45 20 64.30 0.002566
46 21 64.42 0.002338
...
and 32 more lines.# A tibble: 31 x 3
term estimate penalty
<chr> <dbl> <dbl>
1 (Intercept) 4.12 0.000207
2 bedrooms -0.0174 0.000207
3 bathrooms 0.0355 0.000207
4 sqft_living 0.307 0.000207
5 sqft_lot -0.0376 0.000207
6 floors 0.0210 0.000207
7 waterfront 0.191 0.000207
8 view -0.0615 0.000207
9 sqft_above 0.139 0.000207
10 basement -0.0405 0.000207
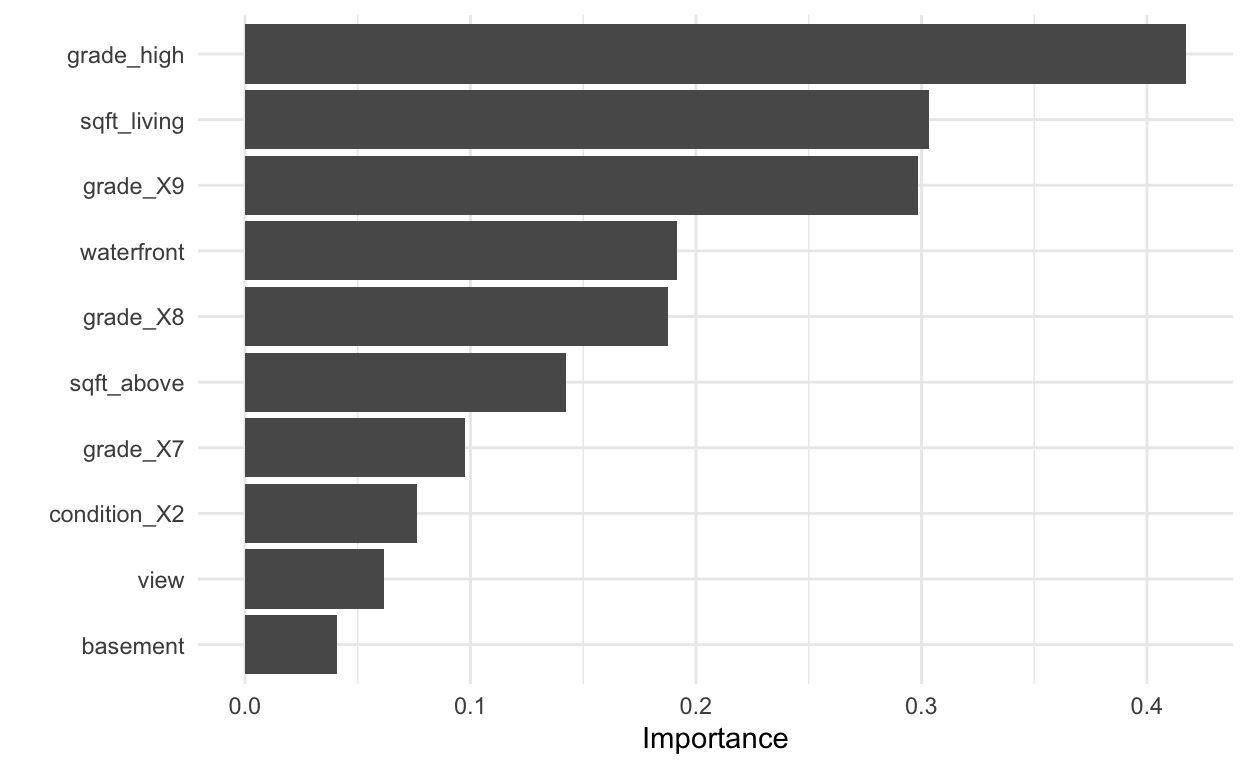
# … with 21 more rowsWe kunnen het belang van de variabele visualiseren
Evalueren op testgegevens
Ten slotte passen we het model toe op de testgegevens en onderzoeken we enkele definitieve metrieken. We tonen ook de metriek van het gewone lineaire model. Het lijkt erop dat de prestaties van het LASSO-model iets beter zijn, maar het scheelt niet veel.
# A tibble: 2 x 4
.metric .estimator .estimate .config
<chr> <chr> <dbl> <chr>
1 rmse standard 0.135 Preprocessor1_Model1
2 rsq standard 0.655 Preprocessor1_Model1# A tibble: 2 x 4
.metric .estimator .estimate .config
<chr> <chr> <dbl> <chr>
1 rmse standard 0.135 Preprocessor1_Model1
2 rsq standard 0.655 Preprocessor1_Model1Bronnen
Dank gaat uit naar verschillende mensen voor het delen van materiaal over tidymodels, waaronder
 En natuurlijk Lisa zelf, haar voeg ik hier zelf aan toe
En natuurlijk Lisa zelf, haar voeg ik hier zelf aan toe

Dit zijn de bronnen die bij deze blog ondersteuning boden:
tidymodels website (Alison Hill, Max Kuhn, Desirée De Leon, Julia Silge)
Uiteraard vooral Lisa Lendway via: